VALL-E, Residual Quantization
아래 글은 비공식적인 개인의 사견임을 밝힌다.
- VALL-E and residual quantization.
- Keyword: VALL-E, EnCodec, Residual Quantization, DDPM, Diffusion
Introduction
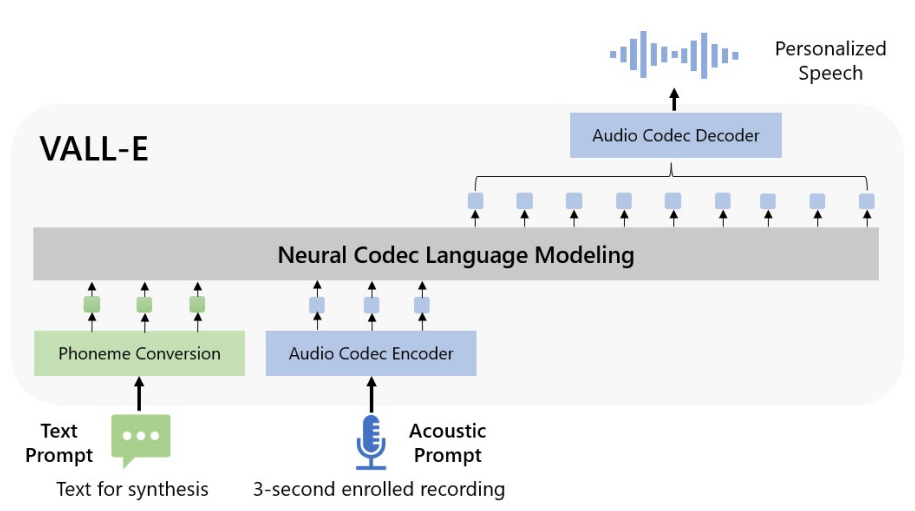
23년 1월 VALL-E[arXiv:2301.02111]라는 One-shot multi-speaker TTS 모델이 나왔다.
TTS는 기본적으로 텍스트를 입력으로 받아 음성을 합성한다. 텍스트는 20~50hz, 음성은 16k~48khz 정도이기에 텍스트와 음성 사이의 correlation을 학습하는 데 어려움이 있다. 이를 해결하기 위해 대부분의 Neural TTS 모델은 중간 매개를 활용한다. 대체로 50~70hz 정도의 spectrogram을 활용하고, text로부터 spectrogram을 생성하는 acoustic model과 spectrogram을 음성 신호로 복원하는 vocoder model의 two-stage 구조를 가정한다.
VALL-E는 중간 매개로 spectrogram 대신 Meta AI의 EnCodec[arXiv:2210.13438]을 활용한다. EnCodec은 neural audio compressor로 quantized vector를 bottleneck으로 두는 Auto-encoder 모델이다.
VALL-E는 text와 reference audio를 입력으로 75hz 정도 되는 quantized vector의 index를 추론하도록 학습하고, EnCodec을 통해 quantized vector에서 audio를 복원한다.
이번 글에서는 EnCodec이 어떻게 vector quantization을 수행하는지와 VALL-E가 이를 어떻게 모델링하는지 논의한다.
Residual Vector Quantization
EnCodec의 기저 논문인 SoundStream[arXiv:2107.03312]은 1초의 음성을 6000bit 안에 저장할 수 있는 Neural Codec 개발을 목표로 하였다. 24khz sampling rate, 16bit rate의 음성이라면 초에 384,000bit가 필요하기에, 6000bit까지 음성을 64배 압축 및 복원할 수 있어야 한다.
VQVAE 아키텍처에 따라 24khz Sampling Rate(이하 SR)의 Audio가 입력으로 들어오면, Encoder를 통해 초당 75프레임까지 길이를 줄인 후(320 Strided-Convolution), Quantization을 통해 Discrete Embedding Vector에 대응시킨다. Embedding Vector는 Decoder를 통해 음성으로 복원된다.
사용자는 Encoder를 통해 Codebook의 인덱스를 대응 및 저장해두었다가, 필요 시점에 인덱스를 Decoder에 통과시켜 원본 음성을 복원하는 Codec인 것이다.
초당 75프레임이라면 프레임 당 80bit 정도의 정보를 할당할 수 있는데(6k = 75 x 80이므로), 기존의 Vector Quantization이라면 Codebook의 크기는 2의 80제곱(1.2e24)이고, 현실적으로 학습이 불가능한 크기이다.
가장 먼저 떠오르는 아이디어는 Wav2Vec2.0[arXiv:2006.11477]과 같이 Product Quantization을 수행하는 것이다. Encoded Vector $e\in\mathbb R^E$가 주어질 때, $e$를 $G$개 벡터로 split하고 $e_i \in \mathbb R^{E/G}\ (i=1,…,G)$ 각각을 Codebook $C_i \in \mathbb R^{N\times V}$에 대응하는 것이다. $G=8$로 잡는다면, 각각의 코드북은 1024개의 엔트리를 가진다($N=2^{10}$). 학습 가능한 크기까지 줄이면서도, 80bit의 데이터를 충분히 활용할 수 있다.
SoundStream은 여기에 하나의 아이디어를 더 얹는다.
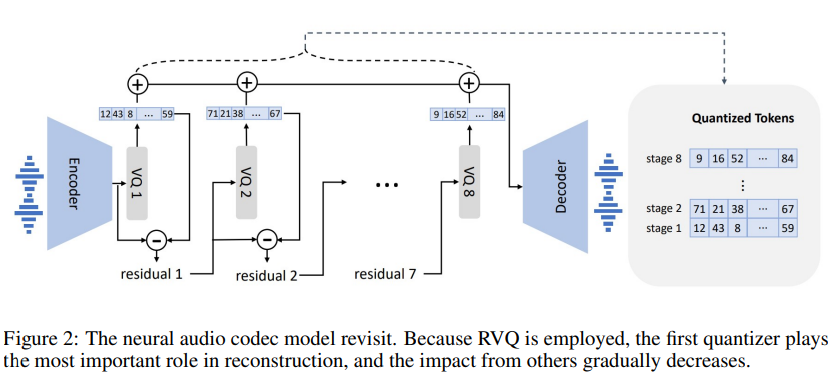
Figure 2. The neural audio codec model revisit. (Wang et al., 2023.)
Encoded Vector $e$를 split 없이 그대로 첫 번째 코드북에 대응한다 $e \mapsto c_1$. 이후 잔차 $r_1 = e - c_1$를 두 번째 코드북에 대응한다 $r_1 \mapsto c_2$. 이렇게 연쇄적으로 잔차 정보에 대응해가는 $(r_{i} = r_{i-1} - c_{i}) \mapsto c_{i+1}$ 방법론을 SoundStream은 Residual Vector Quantization, 이하 RVQ라 정의하였다.
Product Quantization과 Residual Quantization은 대수의 Cartesian Product와 Direct Sum과 같은 관계로 비치기도 한다.
RVQ는 기존 Quantization과 비교하였을 때, bitrate를 조절할 수 있다는 장점을 가진다. 첫 Stage 이후의 Quantization은 잔차값을 대상으로 하기에, $C_1$부터 $C_6$까지 6개 코드북만 가지고 Decoding을 진행해도 발화의 발음이나 기본적인 목소리를 인식하는 데에는 문제가 없기도 하다. 이 경우 프레임당 60bit, 초당 4500bit로 운용 가능한 손실 압축 Codec이다.
이렇게 몇 번 코드북까지를 활용할 것인가에 따라 bitrate를 가변적으로 운용할 수 있다.
VALL-E Decoder
VALL-E는 Zero-shot TTS를 목표로 한다. G2P를 거친 phoneme sequence $x$와 reference audio의 embedding $\tilde c_{t, \le k} = \sum^k_{i=1} \tilde c_{t,i},\ \tilde C = \tilde c_{:, \le 8}$을 입력으로 8개 Codebook의 인덱스를 합성해야 한다.
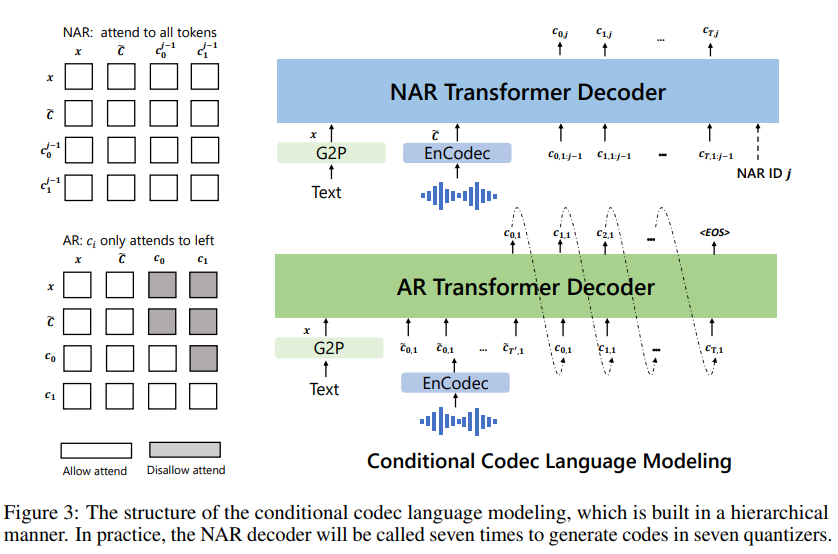
Figure 3. The structure of the conditional codec language model. (Wang et al., 2023.)
첫 번째 코드북의 인덱스는 Autoregressive Manner로 생성한다.
$$p(c_{:, 1}|x, \tilde c_{:, 1}; \theta_{AR})=\prod_{t=1}^T p(c_{t, 1}|x,\tilde c_{:, 1},c_{<t, 1}; \theta_{AR})$$
이후에는 별도의 모델을 하나 더 두어 Parallel(Non-AR) Manner로 생성한다.
$$p(c_{:, {2:8}}|x, \tilde C; \theta_{NAR})=\prod^{8}_{j=2} p(c _{:, j}|x, \tilde C, c _{:, < j}; \theta _{NAR})$$
NAR 모델의 경우 하나의 파라미터로 2번부터 8번까지 7개 Codebook을 모두 커버해야 하므로, 몇 번 Codebook을 합성할 것인지 모델에 inform 할 수 있어야 한다. VALL-E는 Transformer의 Normalization 레이어를 $\mathrm{AdaLN}(h, i) = a_i\mathrm{LayerNorm}(h) + b_i$로 교체하여 $i$번째 Codebook 합성을 유도한다.
Wrap up
VALL-E의 RVQ와 NAR Decoder는 DDPM[arXiv:2006.11239]과 유사한 컨셉을 보인다.
VALL-E의 NAR Decoder와 DDPM은 모두 Corrupted Input에 대한 점진적인 Recovery를 제공한다. VALL-E는 Quantized Embedding에 대해 RVQ Residue를 추정하고, DDPM은 Noised Embedding에 대한 Score를 추정하여 Adaptive Manner로 Signal을 복원해 나간다. (e.g. VDM[arXiv:2107.00630])
$$\mathrm{VDM}: z_{t-1} = \frac{1}{\alpha_{t|t-1}}z_t + \frac{\sigma^2_{t|t-1}}{\alpha_{t|t-1}}score_\theta(z_t; t) \\ \mathrm{RVQ}: c_{j+1} = c_j + nar_\theta(\tilde C, \sum_{i\le j}c_i; j)$$
또한 VALL-E와 DDPM은 모두 Multiple-stage에 대해 동일한 모델을 사용하기 때문에, 현재가 몇번째 Codebook인지/몇번째 timestep인지 inform 하기 위해 Adaptation을 수행한다. 단순히 Embedding을 feature map에 더하기도 하고, Adaptive normalization을 활용하기도 한다.
이를 반대로 활용하면, Image에 대해서도 Discrete Embedding을 기반으로 한 Generative Transformer를 구성해 볼 수도 있을 것이다. (e.g. MaskGIT[arXiv:2202.04200]) Diffusion 모델에 비해 적은 Step으로 competitive한 이미지 생성도 가능할지 기대해 본다.
Reference
- VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers, Wang et al., 2023. [arXiv:2301.02111]
- EnCodec: High Fidelity Neural Audio Compression, Defossez et al., 2022. [arXiv:2210.13438]
- MaskGIT: Masked Generative Image Transformer, Chang et al., 2020. [arXiv:2202.04200]
- SoundStream: An End-to-End Neural Audio Codec, Zeghidour et al., 2020. [arXiv:2107.03312]
- VDM: Variational Diffusion Models, Kingma et al., 2021. [arXiv:2107.00630]
- Wav2Vec2.0: A Framework for Self-Supervised Learning of Speech Representations, Baevski et al., 2020. [arXiv:2006.11477]
- DDPM: Denoising Diffusion Probabilistic Models, Ho et al., 2020. [arXiv:2006.11239]