Survey: Neural TTS and Attention Alignment
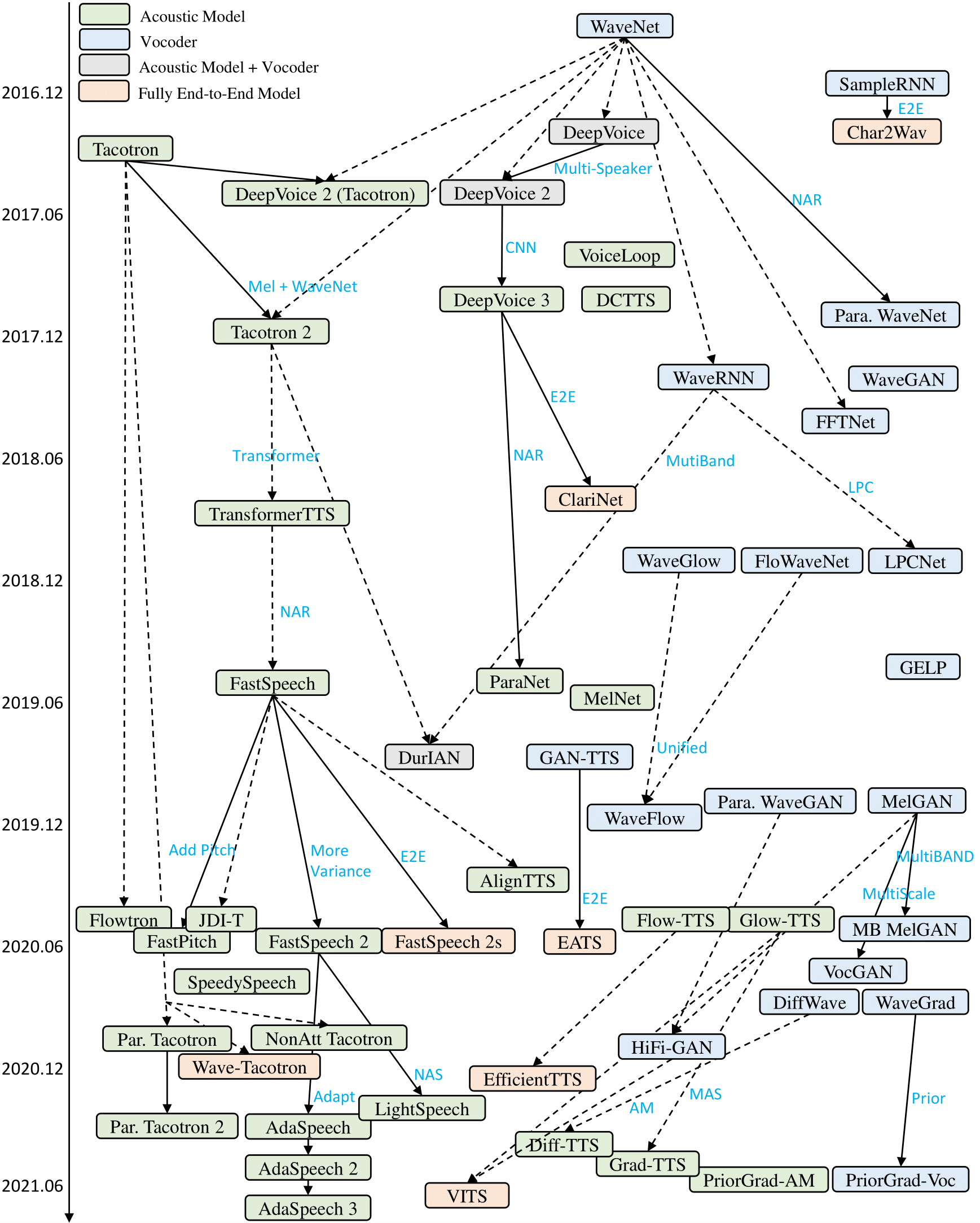
- Survey of Neural Text-to-Speech models and Attention Alignment
- Keyword: TTS, Attention, Alignment
Introduction
16년도 WaveNet[arXiv:1609.03499], 17년도 Tacotron[arXiv:1703.10135]을 기점으로 딥러닝 기반의 음성 합성 TTS 모델들이 현재까지 꾸준히 발전해 오고 있다. 19년도부터 21년도까지 음성 합성 연구원으로 재직하며 보고 느꼈던 TTS의 발전에 관해 정리해보고자 한다.
TTS: Text-to-Speech
TTS는 텍스트를 조건으로 발화 음성을 합성하는 생성 분야를 이야기할 수 있다.
자연에 존재하는 발화 신호는 기계 신호로 양자화하는 과정에서 1초에 몇 개의 샘플을 획득할 것인지의 Sample Rate(이하 SR)와 샘플을 몇 가지 수로 나타낼 것인지의 Bit Rate로 2가지 변수를 가진다.
TTS 합성 분야에서 SR은 과거 16kHz부터, 이후 22.05kHz와 24kHz, 현재 32kHz, 44.1kHz, 48kHz까지 꾸준히 증가해왔다. Nyquist 이론에 근거하면 SR의 절반이 획득할 수 있는 주파대역의 상한이므로, TTS는 과거 최대 8khz에서 24khz까지 점점 더 높은 주파대역을 복원할 수 있게 되었다.
Intermediate representation
TTS가 처음부터 높은 SR의 음성을 생성할 수 없었던 이유는
1.) 1초에 2만여개 프레임을 포함하는 sparse input으로부터 context를 추정할만큼 넓은 receptive field를 가진 아키텍처가 없었고 (WaveNet[arXiv:1609.03499] 이전)
2.) 음소의 발화 시간은 대략 10~50ms으로 1초에 20~50여개 정도이지만, 음성은 1초에 2만에서 4만여개 프레임으로 1k배 정도 길이 차 사이의 관계성을 학습시키기 어려웠으며
3.) 고주파대역으로 갈 수록 임의성이 짙어져 확률 모델 도입 없이 고주파 정보의 구현이 어려웠기 때문이다.
이를 해결하기 위해 TTS 모델은 Spectral feature를 중간 매개로 두고, 텍스트에서 spectral feature을 합성하는 acoustic 모델과 spectral feature로부터 음성을 복원하는 vocoder 모델 2단계 구조를 구성하기 시작했다.
Spectral feature로는 대체로 Short-time Fourier Transform(이하 STFT)으로 구해진 fourier feature의 magnitude 값(이하 power spectrogram)을 활용했다. 오픈소스 TTS 구현체에서는 주로 12.5ms 주기마다 50ms 정도의 음성 세그먼트를 발췌하여 주파 정보로 변환하였다. 이렇게 되면 spectral feature는 1초에 80개 정도의 프레임을 가지고, 텍스트에서 대략 2~4배, 음성까지 250~300배 정도로 구성된다.
Fourier feature를 활용할 수 있었던 이유는
1.) 음성의 발화 신호가 기본 주파수(F0)와 풍부한 배음(harmonics)로 구성되기에 fourier transform을 통해 각 주파대역별 세기를 나타내는 power spectrogram으로 표현하더라도 정보 유실이 크지 않았고
2.) Source-filter 이론에 근거하였을 때 발화 신호 중 발음 성분이 spectral magnitude의 형태(filter)에 상관관계를 가지기 때문에, 텍스트로부터 발음 정보를 만드는 문제로 치환한 것이다.
그럼에도 발음 정보에 대응 가능한 quefrency 영역의 cepstral feature(ex. MFCC)를 사용하지 않은 이유는, 기본 주파수 등의 정보 손실이 커 음성 신호로 복원하는 보코더의 문제 난이도를 어렵게 했기 때문이다.
Log-scale, Mel-filter bank
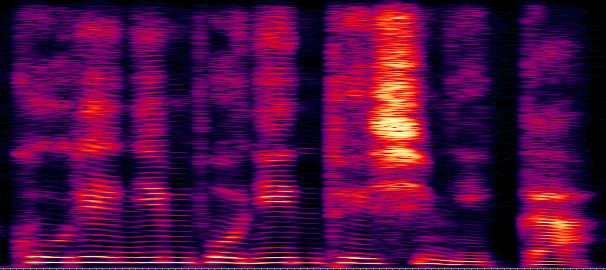
Figure 1: Power spectrogram
대체로 오픈소스 TTS 구현체에서는 STFT의 frequency bins를 1024개 혹은 2048개로 설정한다. 이때 TTS 모델이 합성해야 하는 프레임당 벡터의 길이는 spectral feature 중 허수 반전을 제외한 513개 혹은 1025개이다.
인간의 청각 체계는 음의 세기와 높낮이에 모두 log-scale로 반응한다. 신호의 세기가 N배 커지더라도, 실제로는 logN 정도로 인식하는 것이다. 이를 반영하여 인간이 실제로 듣는 신호의 세기와 높낮이 대역을 강조하기 위해 TTS에서는 power spectrogram (linear spectrogram)을 곧장 활용하기보다는 주파대역의 인지적 선형화를 위해 filterbank를 취하고, 세기의 인지적 선형화를 위해 log를 취한다.
filterbank는 주로 2가지를 활용하는 듯하다. 가장 많이 쓰이는 Mel-scale filterbank와 LPCNet[git:xiph/LPCNet] 등에서 간간이 보이는 Bark-scale filterbank이다. 대체로 오픈소스 TTS 구현체에서는 0Hz ~ 8kHz의 영역을 나눈 STFT 기존 513개~1025개 frequency bins를 80개~100개로 축약하는 mel-scale filterbank를 활용하는 편이다.
Mel-scale filterbank를 활용하는 경우를 log-Mel scale spectrogram이라고 하여, 간략히 mel-spectrogram이라 일컫는다.
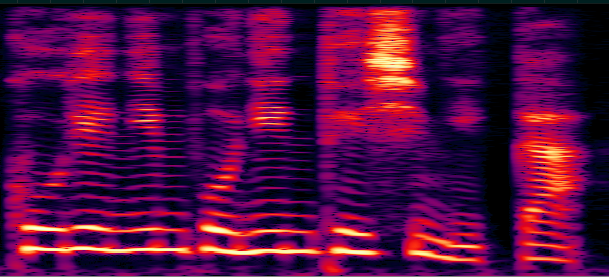
Figure 2: log-Mel scale spectrogram
Vocoding
보코더는 음성을 압축/복원하는 기술을 통칭한다. TTS에서는 algorithmic 하게 구해진 spectrogram(mel-scale)을 음성으로 복원하는 모델을 이야기한다.
단순히 STFT만을 취했다면 발화 신호 특성상 iSTFT만으로도 충분한 음성을 복원해낼 수 있지만, mel-spectrogram 변환 과정에서
1.) 주파대역별 세기를 측정하기 위해 실-허수 신호를 실수 신호로 축약하는 Absolute 연산
2.) 500~1000여개 bins를 80~100개로 압축하는 filter bank 연산의 2가지 손실 압축을 거치기에 algorithmic한 복원에는 한계가 존재한다.
Tacotron[arXiv:1703.10135]에서는 power-spectrogram을 활용하여 filter bank 연산이 없었고, 허수부(phase) 복원에는 griffin-lim 알고리즘을 활용하였다.
상용화하기 어려운 음질이었고, 부족한 주파대역과 허수(phase) 정보 복원을 위해 Tacotron2[arXiv:1712.05884]에서는 2016년 WaveNet[arXiv:1609.03499]을 별도의 경험적 보코더로 두어, mel-spectrogram에서 time-domain signal을 복원하도록 학습하여 활용하였다.
Bit-rate
음성은 과거와 현재 크게 다르지 않게 16bit를 bitrate로 산정하여, 음성 신호를 대략 6만여개 실수로 양자화하였다.
WaveNet을 경량화한 WaveRNN[arXiv:1802.08435]에서는 신호 복원 문제를 6만여개 클래스의 분류 문제로 바꾸고자 했는데, 현실적으로 6만개 클래스를 분류하는 것에는 네트워크 학습에 어려움이 있었다.
이를 위해 시간축 신호 역시 청각 구조에 따른 인지적 선형화를 진행하며 16bit를 8bit로 2차 양자화하였다. 대체로 mu-law를 활용하였으며, 8bit 256개 클래스로 분류하는 보다 쉬운 문제로 치환하였다.
하지만 mu-law 역시 손실 압축이기 때문에, 복원된 8bit 음성을 algorithmic 하게 16bit로 복원하는 과정에서 배경 노이즈가 섞이는 이슈가 있었다.
이는 이후 GAN 기반 신호 복원 방법론인 MelGAN[arXiv:1910.06711] 등이 등장하며 bitrate 상관없이 [-1, 1]의 실수 범위 신호를 직접 복원하게 된다.
Now-on
근래에는 24khz, 32khz, 48khz의 SR과 16bitrate의 데이터셋을 주로 활용하고 있으며, 대체로 1024bins/12.5ms(or 256frame)/50ms(or 1024frame)의 STFT, 80~100bins log-Mel scale spectrogram을 활용하는 듯하다. [git:seungwonpark/melgan, git:jik876/hifi-gan] 아무래도 Tacotron2의 영향이지 않을까 싶다. [git:NVIDIA/tacotron2]
이외로 preemphasis 필터를 거치거나, 기준 세기를 잡아 amplitude 영역의 주파정보를 decibel 단위로 변환하기도 하고, [-1, 1] 범위로 값을 scaling 하기도 한다. [git:keithito/tacotron]
Acoustic Model - Sequence-to-Sequence
Acoustic model은 텍스트에서 mel-spectrogram으로의 가변 길이 Sequence-to-Sequence 모델을 상정한다.
주로 문장 단위로 음성을 전처리하는데, 입력으로 들어온 문장은 표기 문자인 자소를 그대로 쓰기도 하고, 소리 문자인 음소로 변환하여 활용하기도 한다. 이 과정을 grapheme-to-phoneme(이하 G2P)라 하며, [git:Kyubyong/g2p]의 카네기 멜론 대학 음소 사전(CMU-Dictionary)를 활용하거나 [git:bootphon/phonemizer]의 International Phonetic Alphabet(이하 IPA)을 활용하기도 한다.
Sequence-to-Sequence 모델은 기본적으로 Encoder-Alignment-Decoder 3개 모듈로 이뤄진다. 음소/자소 열은 Text Encoder에 들어가게 되고, Alignment를 통해 텍스트와 합성하고자 하는 spectrogram의 관계를 정립/정렬한다. 이후 정렬된 텍스트 인코딩은 Spectrogram Decoder에 의해 mel-spectrogram으로 합성된다.
Encoder와 Decoder를 어떻게 구성할지를 TTS의 Network Backbone 관련 연구에서 다루고, 어떻게 텍스트와 spectrogram의 관계를 정의하고, Alignment 모듈을 학습할 것인지를 Attention Alignment 관련 연구에서 다룬다.
텍스트와 spectrogram의 관계가 다른 Sequence-to-Sequence 태스크와 다른 점은
1.) 발화 특성상 음소가 동일한 문장이어도 사람마다, 녹음마다 발화의 길이가 달라질 수 있어 음소만으로는 발화 길이의 추정이 어려울 수 있다는 점과
2.) 텍스트와 발화 음성 모두 시간 축에 따라 정렬되기 때문에 둘의 관계성이 순증가(monotonic) 하는 특성을 띤다는 것이다.
TTS에서는 이러한 특성을 활용하여 Alignment 모듈을 Joint training 하기도 하고, 외부에서 학습한 모듈을 활용해 Distillation 하기도 한다.
이를 토대로 특성에 따라 TTS를 분류한다면 다음과 같이 나눌 수 있을 것 같다.
- Decoding: Autoregressive, Parallel
- Backbone: CNN, RNN, Transformer
- AR Alignment: Forced-Align, Content-based, Location-based
- PAR Alignment: Distillation, Joint-Distillation, End-to-End
Autoregressive TTS
TTS 모델은 일차적으로 spectrogram의 디코딩 방식에 따라 2가지로 나눌 수 있다. $x_t$를 t번째 spectrogram frame, $c$를 텍스트 입력이라 할 때, Autoregressive 모델은 t번째 프레임 생성에 이전까지 생성한 프레임을 참조하는 방식 $\prod_{t=1}^T p(x_t; x_{\cdot < t}, c)$, Non-autoregressive(or parallel) 모델은 이전 프레임의 참조 없이 텍스트로부터 spectrogram을 합성하는 방식이다 $p(x_{1:T}; c)$.
전자의 경우 대체로 첫 번째 프레임부터 마지막 프레임까지 순차적으로 합성해야 하기에 합성 속도가 느리지만, 이전 프레임을 관찰할 수 있기 때문에 대체로 단절음이나 노이즈 수준이 적은 편이고, 후자는 GPU 가속을 충분히 받아 상수 시간 안에 합성이 가능하지만 상대적으로 단절음이나 노이즈가 발견되는 편이다.
- WaveNet: A Generative Model for Raw Audio, Oord et al., 2016. [arXiv:1609.03499]
Category: Autoregressive, CNN, Forced-Align
Problem: Inefficiency of increasing receptive field
Contribution: Dilated convolution, exponential field size
Future works: Reduce real-time factor(RTF > 1), remove handcrafted features
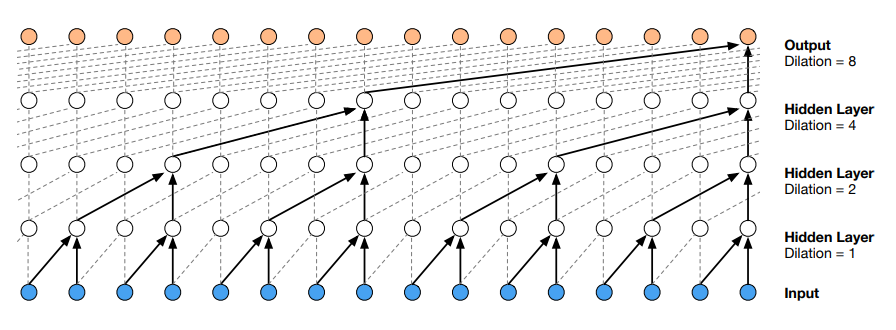
Figure 3: Visualization of a stack of dilated causal convolutional layers. (Wavenet, 2016)
기존까지의 TTS 시스템은 크게 두 가지로 나뉘었다.
1.) Unit-selection/Concatenative: 사전에 녹음된 음성을 규칙에 따라 이어 붙이는 방식
2.) Statistical Parametric TTS: HMM을 기반으로 보코더 파라미터를 추정, 합성하는 방식
이러한 시스템들은 대체로 음소, 음소별 발화 길이, F0 등의 입력을 요구하였고, 그럼에도 기계가 발화하는 듯한 음성을 합성해 내는 특성을 가지고 있었다.
기존까지 음성 신호를 직접 합성하지 않고 보코더 파라미터를 추정하였던 이유는 초당 2만여개 프레임을 감당할만한 receptive field의 현실적 확보가 어려웠기 때문이다. 예로 strided convolution을 활용한다면, receptive field의 크기는 네트워크의 깊이에 비례하고, 2만여개 프레임을 커버하기 위해 2만개의 레이어가 필요하다.
WaveNet은 이를 Dilated convolution(or atrous convolution)을 통해 해결하였다. 인접 프레임을 커널과 합성곱 하는 것이 아닌, N개 프레임마다 1개 프레임을 선출하여 합성곱 하는 방식을 활용한다. 이때 N을 dilation이라고 하며, N을 지수에 따라 늘려가면 receptive field의 크기를 레이어 수의 지수에 비례하게 구성할 수 있다. 2만여개 프레임을 커버하기 위해 14개 레이어면 충분한 것이다.
(jax/flax에서는 input의 dilation을 transposed convolution의 stride, kernel의 dilation을 dilated convolution의 dilation이라고 표현, ref:jax.lax.conv_general_dilated)
이에 신호를 직접처리할 수 있게 되었고, WaveNet은 사전에 구한 음소별 발화 길이와 log-F0를 추가 입력으로 하여 음성 신호를 생성하는 TTS를 구현하였다.
- HMM 기반 TTS 혹은 Forced Aligner을 통해 구한 음소별 발화 길이를 기반으로 텍스트 토큰을 길이만큼 반복, 음성과 정렬 (ex.MFA: Montreal Forced Aligner)
- 반복/정렬된 음소는 conditional input으로 전달
- 이전까지 합성된 음성 프레임을 dilated convolution으로 encoding 하여 최종 다음 프레임을 합성
- 합성은 8bit mu-law에 따라 압축한 음성을 256개 클래스의 분류 문제로 치환
- 합성 과정 중에는 음소별 발화 길이를 텍스트로부터 추정하는 별도의 모듈을 학습하여 활용
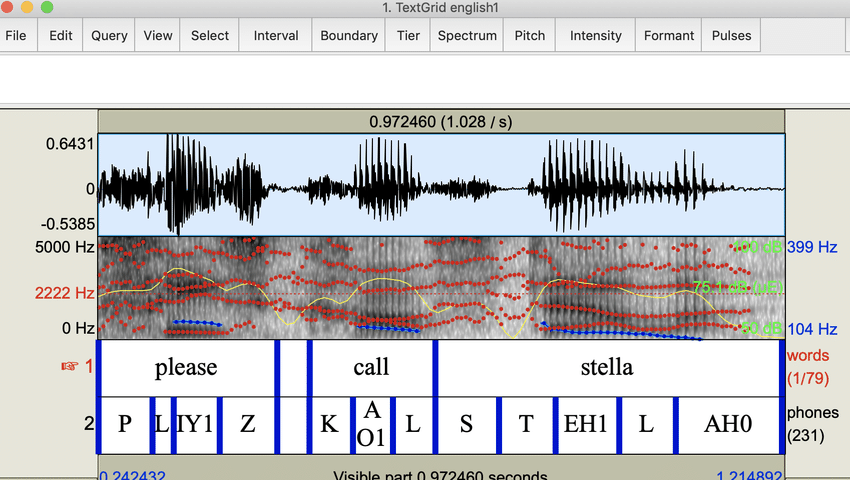
MFA: Text-Speech align sample (ResearchGate, Zhiyan Gao)
WaveNet은 16khz 음성을 대상으로 했기에 1초에 16k개 프레임을 생성해야 했으며, 프레임마다 dilated convolution을 구동해야 했기에 합성 속도가 실시간보다 느린 문제가 있었다. 그럼에도 음성은 기존 시스템보다 자연스러웠으며, 보코더 파라미터가 아닌 음성을 직접 모델링할 수 있었다는 기여를 가진다.
- Tacotron: Towards End-to-End Speech Synthesis, Wang et al., 2017. [arXiv:1703.10135]
Category: Autoregressive, CNN + RNN, Content-based alignment
Problem: Large RTF of Wavenet, handcrafted features required
Contribution: Bahdanau attention, Spectrogram synthesis
Future works: Noisy output, instability of attention mechanism
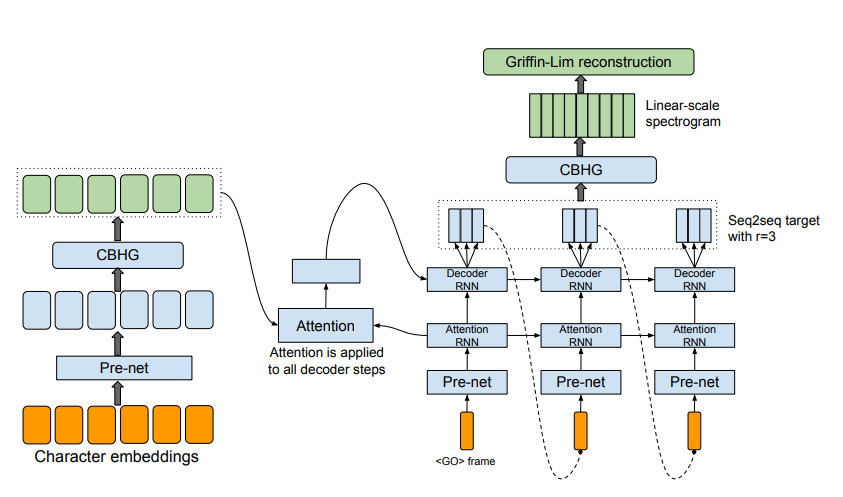
Figure 1: Model Architecture. (Tacotron, 2017)
이후 17년도 구글은 Tacotron이라는 TTS 모델을 공개한다.
1.) Learnable 한 Attention mechanism을 도입하여 음소별 발화 길이가 필요하지 않고
2.) Spectrogram을 생성하도록 목표를 재설정하여,
3.) RNN 기반의 Decoding을 통한 효율화를 가능케 했다.
- Learnable Attention Mechanism
기존까지 TTS는 HMM 등을 활용하여 음소별 발화 구간을 추정하는 별도의 모델을 두고, 이를 통해 음소를 반복, 음성과 정렬하는 방식을 많이 사용하였다. 이 경우 구간 추정 모델과 TTS를 이중으로 학습해야 했기에, Tacotron에서는 Bahdanau et al., 2014.[arXiv:1409.0473]의 Joint training이 가능한 learnable alignment를 활용하였다.
기계 번역(Neural Machine Translation, 이하 NMT) 분야 역시 가변 길이의 Seq2Seq 문제를 상정한다. NMT에서는 생성하려는 토큰과 입력의 관계를 명시하여 학습/추론 과정을 안정화하기 위해 “Alignment"라는 것을 도입하였다. 이는 다음 토큰을 생성하기 위해 입력으로 들어온 텍스트 토큰 중 어떤 것을 관찰할지를 결정하는 Bipartite 그래프의 간선들을 의미한다.
TTS에서는 다음 프레임을 합성하기 위해 텍스트의 어떤 부분을 관찰할지 결정하는 map을 alignment라고 한다. 음소는 대략 20~50ms의 발화 구간을 가지고, spectrogram frame은 대략 10~20ms으로 구성되기 때문에 alignment는 음소 별로 1~3개 프레임을 순차적으로 할당하는 역할을 한다.
이렇게 alignment를 명시하고 명확히 제약할수록 관계 해석에 대한 Encoder와 Decoder의 부하가 줄어 TTS의 학습이 가속화되는 이점이 있다.
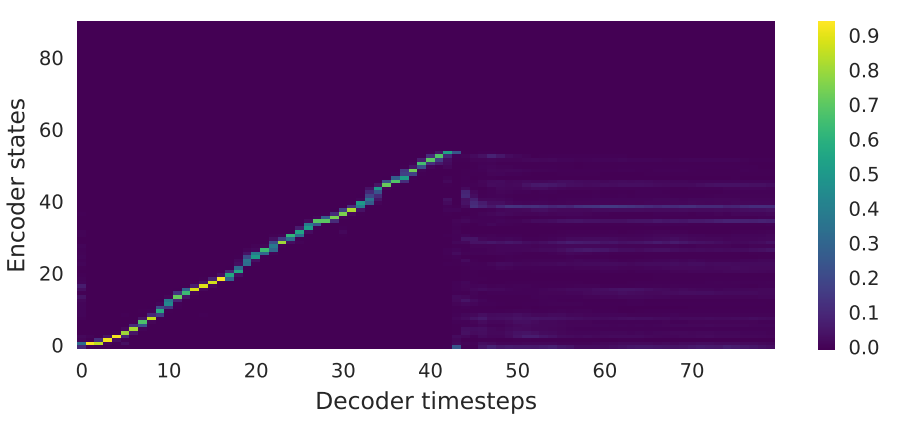
Figure 3: Attention alignments on a test phase. (Tacotron, 2017)
이때 발화는 음소를 순서대로 읽는 방식으로 작동하기 때문에, NMT와 달리 TTS의 Alignment는 순증가(순차 할당) 하는 특성을 가진다.
대체로 Alignment를 활용하는 Autoregressive TTS는 $x_{1:S}$를 S개 음소로 이뤄진 입력 문장, $y_{1:T}$를 T개 프레임으로 이뤄진 출력 spectrogram이라 할 때 다음과 같이 fomulation 된다.
$$\begin{align*} &s_{1:S} = \mathrm{TextEncoder}(x_{1:S}) \in \mathbb R^{S\times C} \\ &q_t = \mathrm{SpecEncoder}(y_{1:t - 1}) \in \mathbb R^{C}\\ &a_{t, \cdot} = \mathrm{Attention}(Wq_t, Us_{1:S}) \in [0, 1]^{S} \\ &h_t = \sum_{i=1}^S a_{t, i}s_i \\ &y_t = \mathrm{SpecDecoder}(q_t, h_t) \end{align*}$$
이렇게 텍스트 $x_s$와 spectrogram $y_t$의 관계성을 나타내는 map $a_{s, t}$을 attention alignment라 부르게 된다. $a_{s, t}$가 0이라면 s번째 음소와 t번째 프레임은 독립인 것이고, 1에 가까울수록 s번 음소에 의해 t번 프레임이 합성될 확률이 높아지는 것이다.
Tacotron에서는 Bahdanau의 alignment mechanism을 그대로 활용한다.
$$\begin{align*} &e_{t, \cdot} = v^T\mathrm{tanh}(Wq_t + Us_{1:S}) \\ &a_{t, \cdot} = \mathrm{softmax}(e_{t, \cdot}) \\ & \mathrm{where} \ W, U \in \mathbb R^{C \times H}, \ v \in \mathbb R^H \end{align*}$$
이러한 alignment mechanism을 additive attention이라고도 하고, 입력 텍스트와 이전 프레임의 정보를 통해서만 alignment를 결정하기 때문에 content-based attention이라고 한다.
별도의 constraint 없이도 정상적으로 학습된 Tacotron은 monotonic 한 alignment로 유도된다. 하지만 monotonic 한 align이 정상적으로 학습되지 않는 경우도 종종 있고(학습 불안정성), 이 경우 Autoregressive Decoding을 통해 음성을 정상 합성할 수 없다.
또한 content-based attention이기 때문에 경우에 따라 문장 내에 동일한 음소가 2개 이상 있는 경우 alignment가 현 발화 시점 이전 혹은 이후의 텍스트에 attending 하기도 한다. 이 경우 반복/누락 등의 발음 오류를 만든다.
![Repeating issue, [discourse.mozilla:julian.weber]](/images/post/surveytts/repeat.png)
Repeating issue, [discourse.mozilla:julian.weber]
- Spectrogram Retarget, RNN-decoding
기존의 WaveNet이 음성 신호를 직접 복원하고자 하였다면, Tacotron은 Spectrogram으로 합성 대상을 변경한다.
앞서 이야기하였듯 spectrogram은 reasonable 한 선택이었다. 기존의 시스템은 높은 SR로 인해 RNN을 학습하는 것이 어려웠고, CUDA 등 GPU toolkit에 의해 well-optimizing 된 프로시져를 활용하지 못하는 아쉬움이 있었다.
spectrogram은 초에 80여 프레임, 이마저도 한 번에 N개 프레임을 동시에 디코딩하는 reduction heuristic을 적용하면 80/N개 프레임으로 축약된다. Tacotron에서는 N=2를 가정하며, 초에 40개 프레임을 구성한다. 20~40개 음소로 구성되는 텍스트와도 관계성이 단순해져 Bahdanau attention의 부하도 줄일 수 있다.
또한 초당 프레임 수가 줄어들었기에 Decoder을 RNN으로 구성할 수 있고, GPU toolkit의 최적화된 연산을 충분히 활용하여 실시간에 가깝게 합성할 수 있다.
다만 기존 WaveNet과 달리 spectrogram을 활용할 경우 별도의 음성 복원 방법론이 필요했고, Tacotron에서는 linear spectrogram을 생성, griffin-lim 알고리즘을 통해 phase를 복원하는 방식을 채택하였다.
대체로 속도는 빨라졌지만, griffin-lim을 통해 복원된 음성은 기계음이 섞인 음성을 만들어내는 이슈가 있었다.
- End of decode
Autoregressive decoding에서 가장 중요한 것은 종료 시점이다. WaveNet에서는 발화 길이에 따른 forced alignment를 활용하여 decoding 전에 신호의 길이를 미리 알 수 있다. 하지만 Bahdanau attention을 쓰는 Tacotron에서는 align과 decoding이 동시에 이뤄지기 때문에 decoding 과정에서 음성의 길이나 종료 시점을 추정할 수 있어야 한다.
Tacotron 구현체에서는 종료 시점에 관해 몇 가지 휴리스틱을 활용하는데,
1.) 묵음에 해당하는 spectrogram이 일정 프레임 이상 합성되면 정지하거나 [git:r9y9/tacotron_pytorch]
2.) Alignment가 텍스트의 마지막 토큰에서 일정 프레임 이상 머무르면 멈추기도 하고,
3.) 음소당 3~5개 프레임을 합성한다는 배경지식을 토대로 음성의 길이를 “음소의 수 x 4” 정도로 설정하여 고정된 길이를 합성하기도 한다.
그리고 이 3가지 방법론에는 모두 단점이 존재한다.
1.) 임계치를 잘못 설정하면 쉼표나 띄어쓰기의 묵음부에서 디코딩이 멈추기도 하고,
2.) 앞서 이야기한 alignment 반복 등의 이슈로 무한히 디코딩하는 현상이 발생하거나
3.) 음성 길이 추정에 실패해 합성 도중에 강제 종료되기도 한다.
이후 논문들에서는 이러한 종료 시점에 관한 엔지니어링 코스트를 줄이기 위해 별도의 방법론을 도입하기도 한다.
- Tacotron2: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions, Shen et al., 2017. [arXiv:1712.05884]
Category: Autoregressive, CNN + RNN, Location-sensitive alignment
Problem: Spectorgram inversion, Content-based attention
Contribution: Location-sensitive attention, WaveNet vocoder
Future works: Unconstrained monotonicity, stop token misprediction
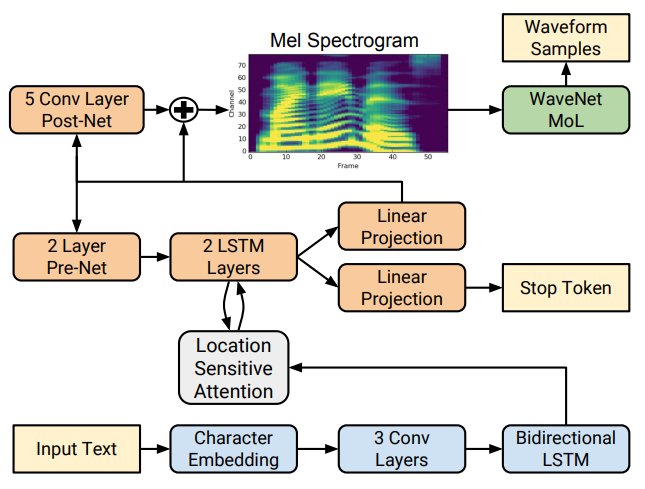
Figure 1: Block diagram of the Tacotron 2 system architecture. (Tacotron2, 2017)
Tacotron2는 Tacotron의 후속작으로 Neural TTS의 가장 기본적인 baseline을 제시한다.
- Mel-spectrogram retarget, WaveNet Vocoder
기존의 Tacotron은 Linear spectrogram과 griffin-lim을 활용하였다. 하지만 앞서 이야기하였듯 linear spectrogram은 인지적 선형화가 이뤄지지 않은 feature이고, 강조될 필요 없는 고주파 대역까지의 복원을 목표로 해야 하기에 Decoder의 network capacity를 높여야 하는 등의 이슈가 있었다.
Tacotron2에서부터는 mel-spectrogram을 활용하여 기존 500bins spectral feature를 80bins까지 압축하였고, network capacity를 덜 고려한 단순한 아키텍처로도 음성 모델링이 가능케 했다.
가장 큰 문제는 mel-spectrogram이 linear-spectrogram에 비해 압축률이 높은 feature라는 것이고, 이를 음성으로 복원하기 위해서는 별도의 경험적 보코더가 필요했다.
Tacotron2에서는 이를 위해 mel-spectrogram을 조건으로 time-domain의 음성 신호를 복원하는 WaveNet을 학습하여 보코더로 활용하였다.
Neural TTS는 Tacotron2 이후 mel-spectrogram을 생성하는 acoustic 모델과 음성 신호를 복원하는 vocoder 모델 2개의 분야로 세분화되었다. NVIDIA에서는 Tacotron2의 구현체[git:NVIDIA/tacotron2]를 공개하였고, [git:seungwonpark/melgan] 등의 오픈소스 보코더가 NVIDIA 구현체와의 호환을 지원하면서 Tacotron2의 세팅은 학계의 pivot처럼 작동하였다.
- Location-sensitive attention
기존의 Tacotron은 content-based additive attention을 상정하였다.
$$a_{t, \cdot} = \mathrm{softmax}(v^T\mathrm{tanh}(Wq_t + Us_{1:S}))$$
음성은 문자를 순차적으로 발화한 신호이기 때문에, TTS 혹은 ASR(Automatic Speech Recognition, 음성 인식) 분야에서는 Alignment가 시간 축에 따라 순증가 해야 한다는 사전 지식이 존재한다.
하지만 $q_t$와 $s_{1:S}$로만 이뤄진 alignment mechanism은 연산에 순증가의 사전 지식이 반영되어 있지 않다.
[arXiv:1506.07503]에서는 ASR에 이러한 순증가의 사전 지식을 적용하기 위해 다음과 같은 formulation을 제안한다.
$$a_{t, \cdot} = \mathrm{softmax}(v^T\mathrm{tanh}(Wq_t + Us_{1:S} + F \ast a_{t - 1, \cdot}))$$
$\ast$는 convolution 연산으로, 이전의 alignment에 convolution을 취해 energy 연산에 더하는 방식이다.
간단한 예로 F가 크기 3의 [1, 0, 0] 커널이어서 PyTorch 기준 F.conv1d(a[:, None], [[[1, 0, 0]]], padding=1)의 연산으로 구현된다면, 이는 F.pad(a, [1, -1])로 alignment의 modal이 다음 텍스트로 이동한 것과 동치가 된다.
즉 과거 alignment를 convolution하는 것은 alignment의 이동 방식에 관한 prior knowledge를 연산에 반영하는 것이고, content-based attention에 비해 상대적으로 안정적인 alignment 학습과 추론이 가능해진다.
이렇게 과거 alignment를 활용하는 방식을 cumulative attention이라고도 하고, location-sensitive attention이라고도 한다.
하지만 이 역시 kernel F의 작동 방식을 완전히 순증가 하도록 제약한 것이 아니기 때문에 기존 보다는 완화되었지만 여전히 반복과 누락 등의 이슈가 발생한다.
이후 [git:coqui-ai/TTS] 등의 오픈소스에서는 순증가의 제약을 강제하기 위해 이전 align 시점의 근방에 대해서만 softmax를 취하는 휴리스틱을 적용하기도 한다.
# PyTorch
# previous_align: [B, S]
# energy: [B, S]
for i, p in enumerate(previous_align.argmax(dim=-1)):
energy[i, :p] = -np.inf
energy[i, p + 3:] = -np.inf
# [B, S]
align = torch.softmax(energy, dim=-1)
- Stop-token prediction
Tacotron에서는 decoding의 종료 시점을 명시적으로 모델링하지 않아 여러 heuristic에 따라 종료 시점을 판단해야 했다.
Tacotron2에서는 NLP의 End-of-sentence(이하 EOS) 토큰과 유사히 어느 시점부터 합성을 종료할지 판단하는 Stop token을 명시적으로 모델링한다.
가변 길이 시퀀스는 배치로 묶는 과정에서 패딩을 붙여 고정된 크기의 텐서로 변환하는데, spectrogram이 존재하는 부근을 false, 패딩이 존재하는 부근을 true로 하는 binary classification 문제를 decoding 할 때마다 추론하게 하는 것이다.
이렇게 되면 decoding 과정에서 프레임마다 stop token을 추론하여 decoding을 지속할지 멈출지 판단할 수 있는 근거로 작동시킬 수 있다.
하지만 이 역시도 모델의 판단에 맡기는 것이기 때문에 합성 중 잘못 추론하는 경우 조기 종료되거나 장기화되는 이슈가 발생할 수 있다. 이에 stop token이 연속 N번 발생하면 종료하는 heuristic을 설정하여 안정성을 높이는 방식을 채택하기도 한다.
대체로 Align과 Autoregressive Decoding을 동시에 진행하는 모델은 종료 시점에 대한 엔지니어링 이슈가 상시 발생할 수밖에 없다. 이는 추후 TTS field가 AR 모델에서 병렬 합성 모델로 이동하는 원인이 되기도 한다.
AR TTS - Architecture
Tacotron2가 Neural TTS의 baseline으로 선정된 이후 TTS의 백본 네트워크를 어떻게 잡는 것이 합성 품질을 높이는가의 추가 연구가 있었다.
- DCTTS: Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention, Tachibana et al., 2017. [arXiv:1710.08969]
Category: Autoregressive, CNN, Content-based alignment
Contribution: CNN-based architecture, SSRN
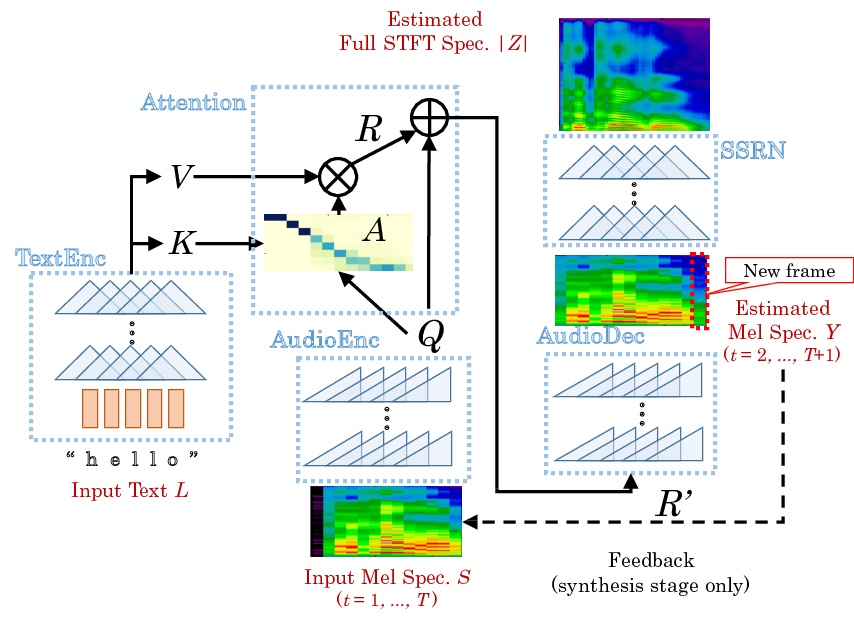
Figure 1: Network Architecture. (DCTTS, 2017)
DCTTS는 그중에서 전체 아키텍처를 convolution으로 구성한 TTS 모델이다.
특이한 점 한가지는 attention alignment에 additive attention이 아닌 dot-product attention을 썼다는 것이다. 이 경우 역시 monotonicity에 관한 prior knowledge는 연산상에 반영되지 않는다.
$$a_{t, \cdot} = \mathrm{softmax}(K^TQ/\sqrt d) \ \ \mathrm{where} \ \ K=Us_{1:S}, \ Q = Wq_t$$
저자는 대신 guided-attention loss라는 목적 함수를 제시한다. attention alignment가 “nearly diagonal"이 되도록 유도하는 방식으로, monotonic한 alignment가 대각 성분에서 값을 가지는 꼴로 표현되는 현상을 구현한 것이다. 연산 상에서 순증가성을 반영하지는 않았지만, 목적함수를 통해 유도하는 방식으로 학습 안정성을 도모한다.
$$\mathcal L_\mathrm{att}(A) = \mathbb E_{t, s}[A_{t, s}W_{t, s}] \\ \mathrm{where} \ \ W_{t, s} = 1 - \exp\{-(t / T - s / S)^2/g^2\}$$
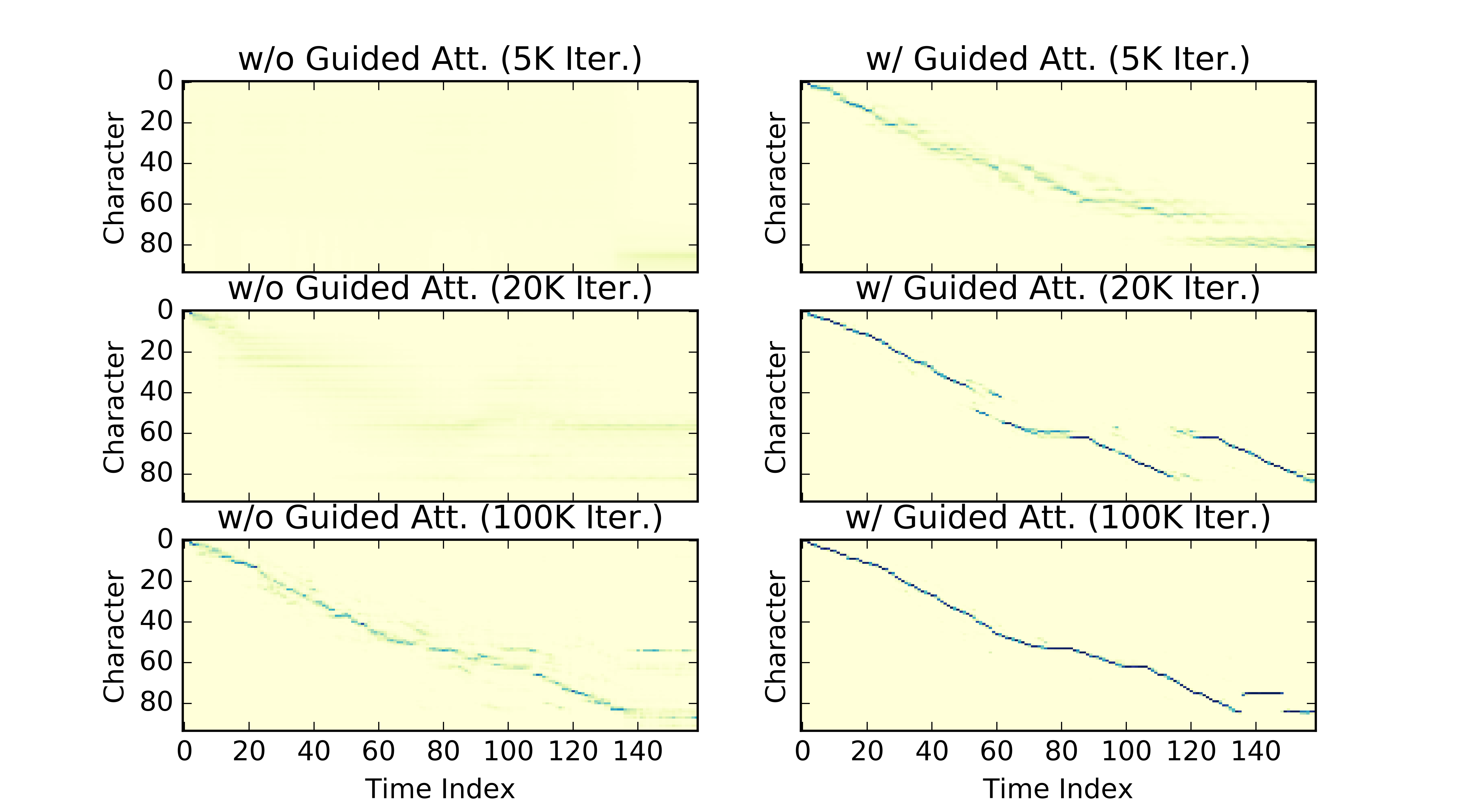
Figure 3: Comparison of the attention matrix. (DCTTS, 2017)
또 한 가지 특이한 점은 SSRN: Spectrogram Super-resolution Network를 활용한 점이다.
DCTTS에서는 mel-spectrogram을 1/4배로 downsampling(mean-pool)한 결과물을 spectrogram decoder가 생성하도록 학습한다. 대체로 음소 1개에 대응되는 spectrogram은 4개 프레임인 것에 착안하여 텍스트의 길이와 downsampling된 spectrogram의 길이 비가 대략 1대1이 되도록 구성한 것이다.
대신 생성된 1/4-scale의 spectrogram을 원본 길이로 복원하기 위해 별도의 경험적 upsampler를 구성하며, 이것이 SSRN이다. 기본적으로 autoregressive decoding은 연산 비용이 높기 때문에, AR decoding에서는 downsample된 spectrogram을 합성하고, SSRN에서는 parallel한 convolution 연산을 상정하여 연산을 가속한 것으로 보인다.
Tacotron의 reduction heuristic이 한 번에 N개 프레임을 합성하는 대신 iteration을 T/N으로 줄였다면, DCTTS는 T/N개 프레임을 합성한 후에 T개 프레임으로 SR 하는 방식을 차용했다는 차이점이 있다.
- TransformerTTS: Neural Speech Synthesis with Transformer Network, Li et al., 2019. [arXiv:1809.08895]
Category: Autoregressive, Transformer, Content-based alignment
Contribution: Transformer-based architecture
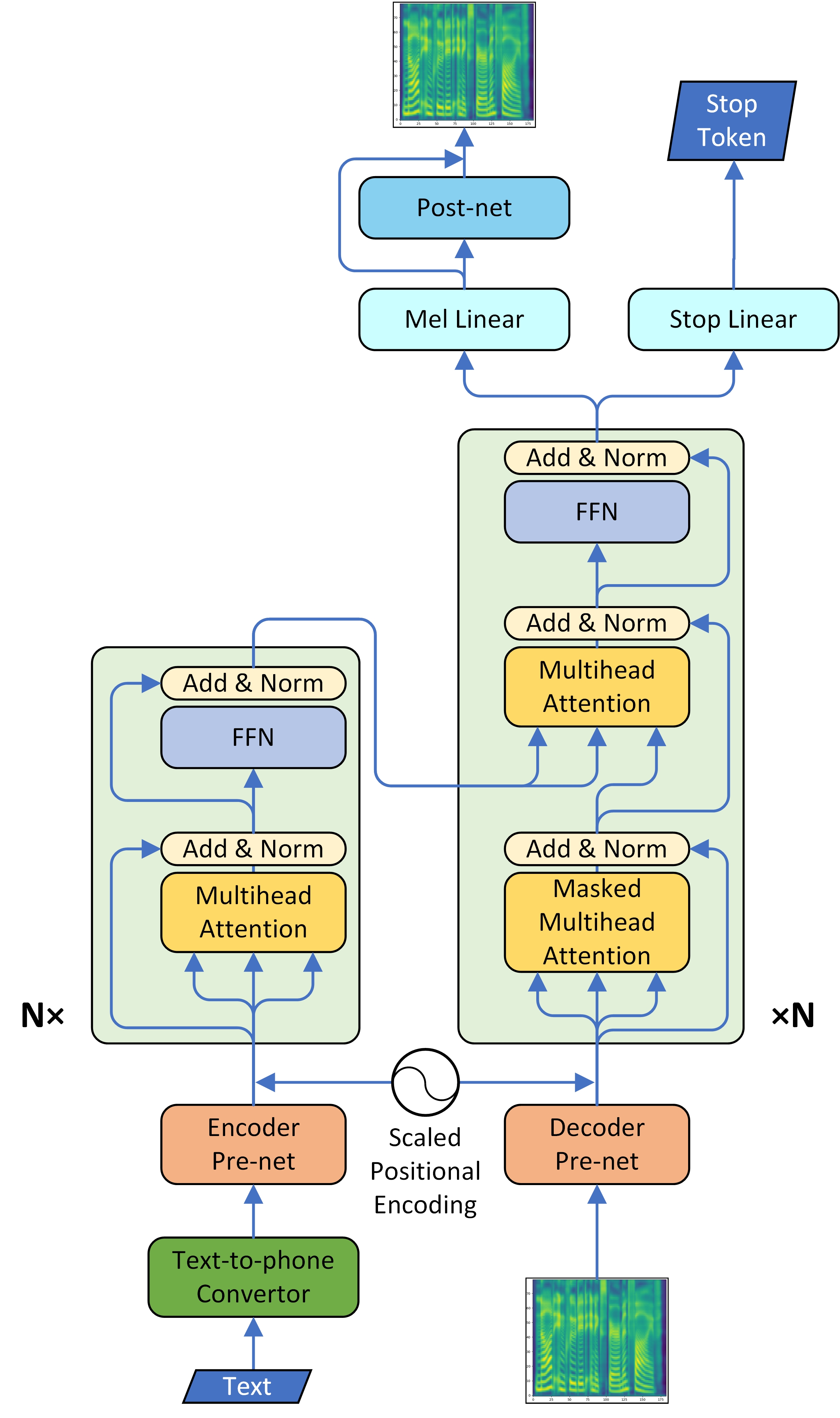
Figure 3: System architecture of our model. (TransformerTTS, 2018)
Transformer TTS는 engineering 관점에서 연구가 많이 이뤄졌다.
Sinuositional encoding의 범위는 [-1, 1]인 것에 반해, Prenet의 output이 ReLU일 경우 $[0, \infty]$의 범위를 가져 feature map의 center point가 다르게 잡히는 현상이 발생했고, 이것이 실제 성능 저하로 이뤄짐을 확인했다. 저자는 이를 방지 하기 위해 prenet에 projection layer를 추가하고 PE 앞에 weighted term을 두었다.
$$l_i = W\mathrm{prenet}(x_i) + \alpha PE_i$$
Stop token prediction에서는 true와 false의 비율이 다른 unbalanced classification 문제임을 지적하였고, 패딩에 해당하는 true 케이스의 목적함수에 가중치를 곱하였다고 이야기한다.
Transformer TTS도 DCTTS와 마찬가지로 dot-product attention을 활용하였다. 다른 점은 Transformer에서 제안한 multihead attention을 활용한 점이다.
개인적인 경험으로는 TTS에서 attention이 여러 개일 때 monotonicity가 유도되는 alignment map은 대체로 1개만 나오는 편이다. 나머지 alignment들은 해석이 불가능하거나, 무의미한 경우가 많다. 저자는 attention head가 4개일 때 보다 8개일 때 MOS가 높았다고 이야기하였다. 이 경우 어떤 이유에서 좋아진 것인지, single-head일 때와 multi-head일 때의 alignment plot을 첨부해주었다면 어땠을까 하는 아쉬움이 있다.
AR TTS - Alignment
Content-based attention의 문제점이 지적되며, attention의 순증가성을 연산에 어떻게 강제할 것인지, content를 energy 연산에서 제거할 수 있는지의 추가 연구도 있었다.
- Forward Attention in Sequence-to-sequence Acoustic Modeling for Speech Synthesis, Zhang et al., 2018. [arXiv:1807.06736]
Category: Location-sensitive alignment
Problem: Training instability, lack of monotonicity prior
Contribution: Forcing monotonicity
Future works: Content inputs
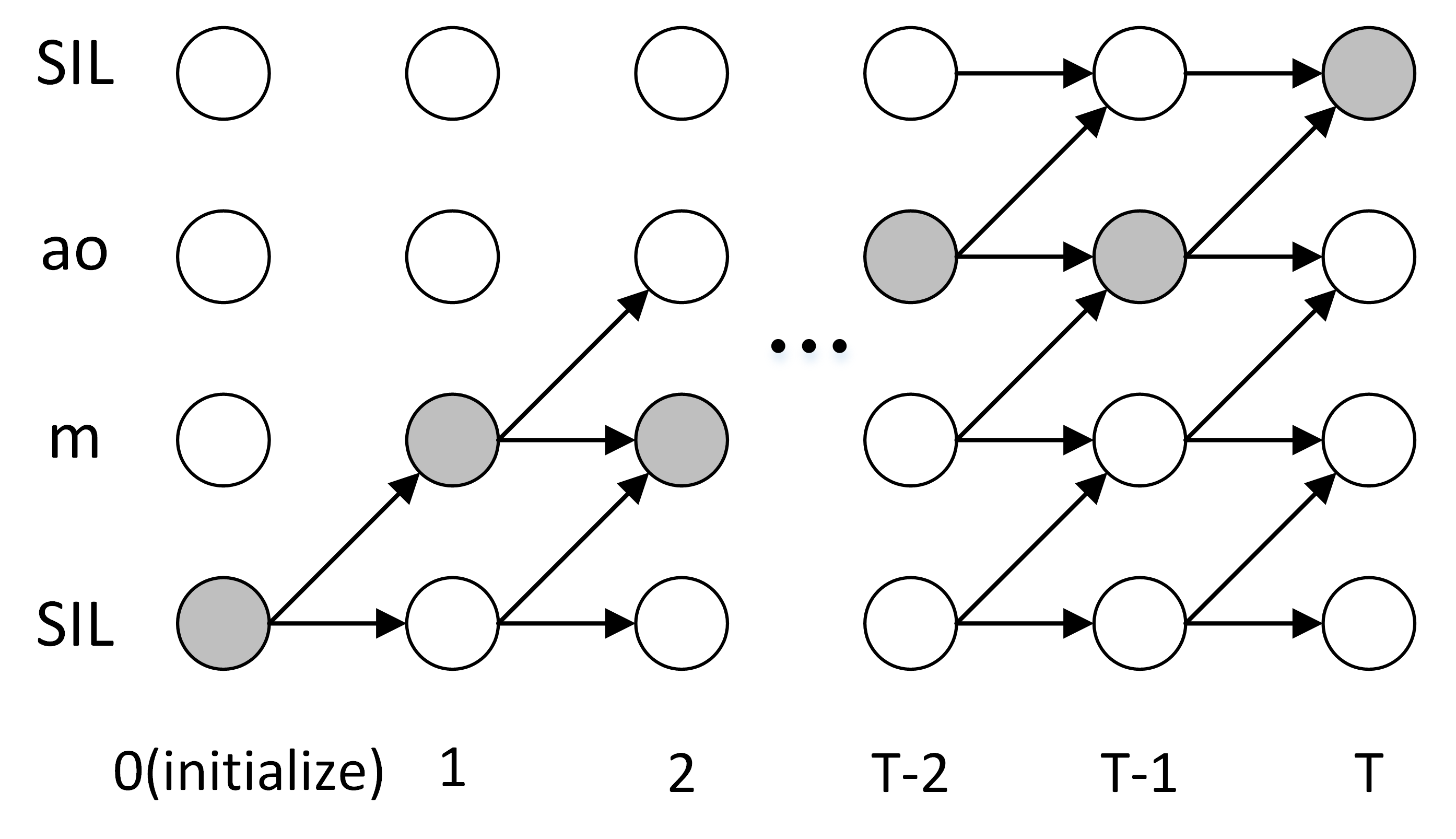
Figure 1: Grey circles represent a possible alignment path. (Forward Attention, 2018)
Forward attention은 CTC(Connectionist Temporal Classification, Graves et al., 2016.)에서 영감을 받아, 현재의 attending phoneme에서 다음 음소로 이동할지, 현재의 음소에 남아 있을지를 확률로 판단하고자 한다.
Content-based attention은 TTS가 기존까지 어떤 음소들을 attending 하였는지 고려하지 않고, 현재 시점에서 가장 가능도가 높은 지점을 선택한다. 하지만 alignment의 연속성과 순증가를 기저로 한다면, 현재의 attending point는 이전 프레임의 attending point와 현재 시점의 가능도를 모두 고려해야 한다.
- 연속성(Continuity): 음소의 누락 없이 alignment는 모든 음소를 순차적으로 1회 이상 attending 해야 한다.
- 순증가(Monotonicity): alignment의 attending point(가장 확률이 높은 지점)는 양의 방향으로만 이동한다.
예로 t번 프레임에서 s번 음소가 attending 될 확률은 t-1번 프레임의 s-1번 확률(이동)과 s번 확률(유지)을 더한 후, content 상에서 t번 프레임의 s번 확률(실체화 가능성)을 곱해야 한다. 과거 프레임에 의해 전이될 확률을 더하고, 실체화될 가능성을 곱하는 것이다.
즉 “content 상에서 실체화될 가능성”(=content-based energy)과 “continuity & monotonicity에 의해 attending 될 가능성”(=attending probability)을 분리한다. 이렇게 되면 기존 content-based attention과 달리 연속성과 순증가의 기저에 따라 attending될 가능성을 고려할 수 있다.
content-based energy를 $y$, attending probaility를 $a$라 하면 다음과 같이 표현 가능하다.
$$\begin{align*} &y_{t, \cdot} = \mathrm{softmax}(v^T\mathrm{tanh}(Wq_t + Us_{1:S})) \\ &a_{t, s} = (a_{t - 1, s - 1} + a_{t - 1, s})y_{t, s} \\ &\hat a_{t, s} = a_{t, s} / \sum^S_{i=1} a_{t, s} \\ &h_t = \sum^S_{i=1}\hat a_{t, i}s_i \end{align*}$$
위 표현은 이동 확률$\alpha_{t-1, s-1}$과 유지 확률$\alpha_{t - 1, s}$을 동일하게 0.5로 보고 있다. Forward attention에서는 이동 확률과 유지 확률 또한 학습 가능한 대상으로 보았고, transition agent $u$라는 확률을 도입한다.
$$a_{t, s} = (u_{t - 1}a_{t - 1, s - 1} + (1 - u_{t - 1})a_{t - 1, s})y_{t, s}$$
경우에 따라 content-based energy를 location-sensitive attention 꼴로 formulation 하기도 한다. attending 확률을 분리한 것과 별개로, energy의 연산상에도 monotonicity가 반영될 수 있도록 유도하는 것이다.
$$y_{t, \cdot} = \mathrm{softmax}(v^T\mathrm{tanh}(Wq_t + Us_{1:S} + F\ast y_{t - 1}))$$
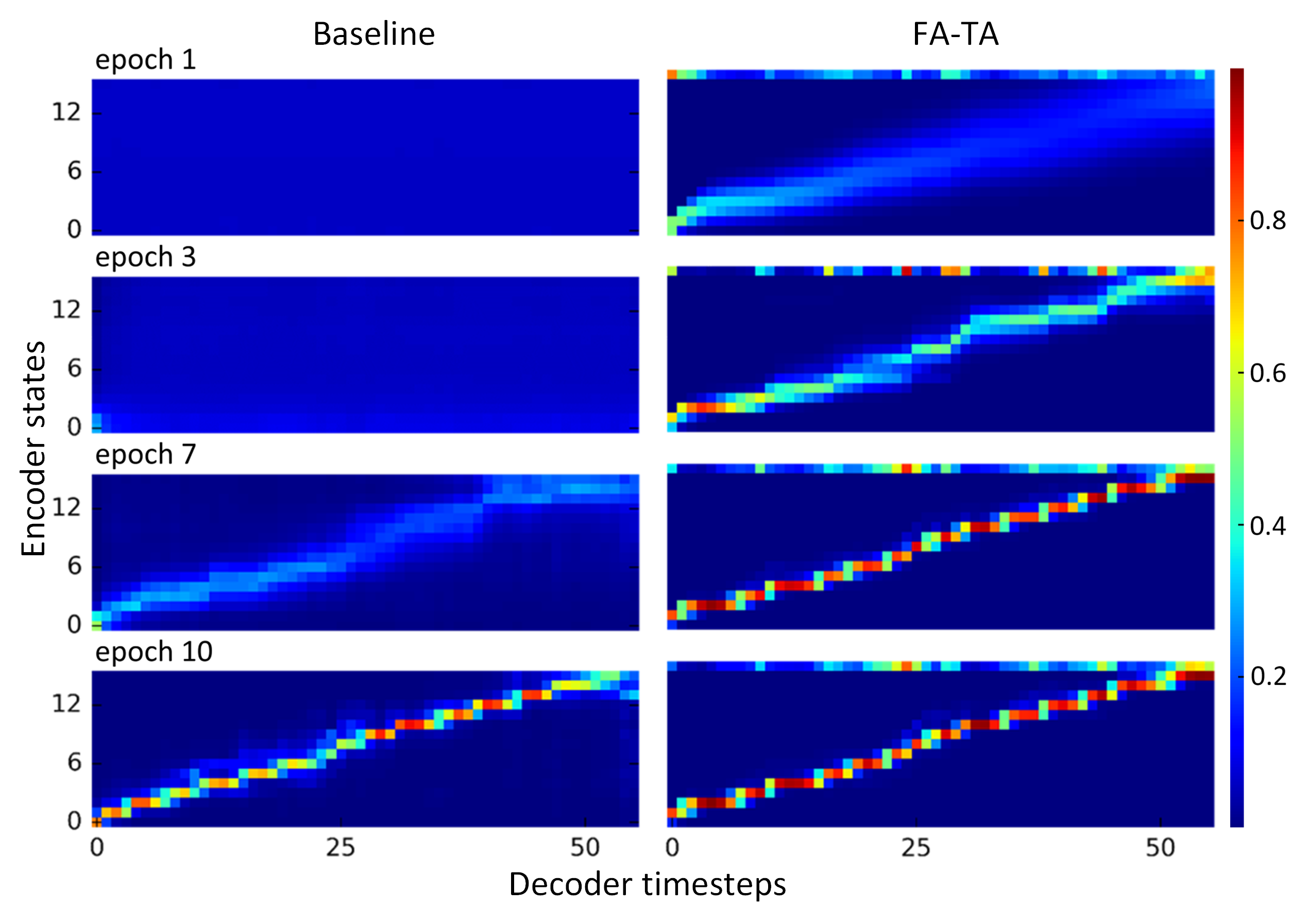
Figure 2: Alignmnts of an utterance. (Forward Attention, 2018)
Forward attention은 alignment map의 확률적 표현을 통해 alignment에 continuity와 monotonity를 부여하였다. 이를 통해 실제 학습 안정성은 더욱 올라왔고, 기존 보다 확률이 양단화된 hard한 attention의 꼴로 표현되었다.
그럼에도 강제하는 수준은 아닌만큼 여전히 이전 프레임의 attending point를 기반으로 alignment map을 마스킹하기도 한다.
- DCA: Location-Relative Attention Mechanisms For Robust Long-Form Speech Synthesis, Battenberg et al., 2019. [arXiv:1910.10288]
Category: Location-sensitive alignment
Contribution: Remove contents from energy
Attention alignment는 대체로 장기성 문제를 가지고 있었다. 문장의 길이가 길어질수록 누락/반복 등의 합성 실패 확률이 높아지는 것이다. DCA에서는 이를 해결하기 위해 2가지 방법론을 제안한다.
- GMM-based Attention
하나는 attending point를 직접 가정하는 방식이다. 기존까지는 content를 기반으로 energy를 계산했다면, 이번에는 content를 통해 몇번째 음소를 attending할지 직접 추정하는 것이다.
Network $P_\theta$는 query와 text encodings를 통해 $\mu_t$번째 프레임을 attending 할 것이라고 명시한다. 이후 alignment는 Gaussian likelihood를 통해 $\mu_t$를 기준으로 weight가 확산되는 꼴로 표현된다.
$$\begin{align*} &\alpha_{t, s} = \mathrm{softmax}\left(-\frac{(s - \mu_t)^2}{2\sigma_t^2}\right) \\ &\mathrm{where} \ \ \mu_t, \sigma_t = P_\theta(Wq_t, Us_{1:S}) \end{align*}$$
이 때 monotonicity와 continuity는 $\mu_t$를 이동량 $\delta_t$로 표현하여 자연스럽게 획득할 수 있다.
$$\begin{align*} &\delta_t, \sigma_t = P_\theta(Wq_t, Us_{1:S}) \\ &\mu_t = \mu_{t - 1} + \delta_t \ \ \mathrm{where} \ \ \delta_t \in [0, 1]\end{align*}$$
DCA에서는 하나의 프레임이 multiple point를 attending할 수 있다는 가정 아래, unimodal gaussian을 multimodal gaussian mixture로 확장한다. 이를 GMM-based attention이라 부른다.
$$\alpha_{t, s} = \sum^{K}_{k=1}\frac{w _{t, k}}{Z _{t, k}}\exp\left(-\frac{(s - \mu _{t, k})^2}{2\sigma _{t, k}^2}\right)$$
- Dynamic convolution attention
다른 하나는 energy 연산에서 직접적인 content의 영향력을 배제하는 것이다.
$$a_{t, \cdot} = \mathrm{softmax}(v^T\mathrm{tanh}(Wq_t + Us_{1:S} + F \ast a_{t - 1, \cdot}))$$
기존까지의 location-sensitive attention은 $Wq_t$와 $Us_{1:S}$를 통해 content의 직접적 영향력을 행사한다. 이는 query가 과거의 context에 매칭되었을 때 alignment가 backward 할 수 있다는 문제점을 가진다.
이를 방지하기 위해 content 요소를 완전히 제거하면, alignment는 location convolution을 통해 항상 고정된 만큼만 움직일 수 있다. 이를 해결하기 위해 제안된 것이 dynamic convolution이다.
$$\begin{align*} &a_{t, \cdot} = \mathrm{softmax}(v^T\mathrm{tanh}(F\ast a_{t - 1, \cdot} + \mathcal G_\psi(h_{t - 1}, q_t) \ast a_{t - 1})) \\ &h_t = \sum^S_{i=1}a_{t, i}s_i \end{align*}$$
dynamic convolution은 network $\mathcal G_\psi$를 통해 kernel을 생성하여 convolution 연산을 수행한다. 이렇게 weight를 런타임에 생성하는 네트워크를 hyper network라고도 부른다.
DCA에서는 content 정보를 에너지에 직접 반영하는 대신, content를 기반으로 alignment를 얼마나 움직일지 추정한다. 이렇게 되면 query와 text를 직접 매칭하지 않기 때문에 content에 의한 backward를 방지하면서, query를 기반으로 현시점이 attending point를 이동할 시점인지 추정할 수 있게 된다.
하지만 이 역시 $\mathcal G_\psi$의 추정에 따라 attending point가 backward로 이동할 수 있다. DCA는 이를 방지하기 위해, 항상 앞으로 움직이는 고정된 kernel $\mathcal P$를 prior로 제공한다.
$$a_{t, \cdot} = \mathrm{softmax}(v^T\mathrm{tanh}(F\ast a_{t - 1} + \mathcal G_\psi(h_{t - 1}, q_t) \ast a_{t - 1} + \mathcal P \ast a_{t - 1}))$$
prior kernel $\mathcal P$는 beta bernoulli의 likelihood 값을 활용하며, 다음은 prior kernel을 convolution 했을 때의 실제 alignment 이동을 도식화한 것이다.
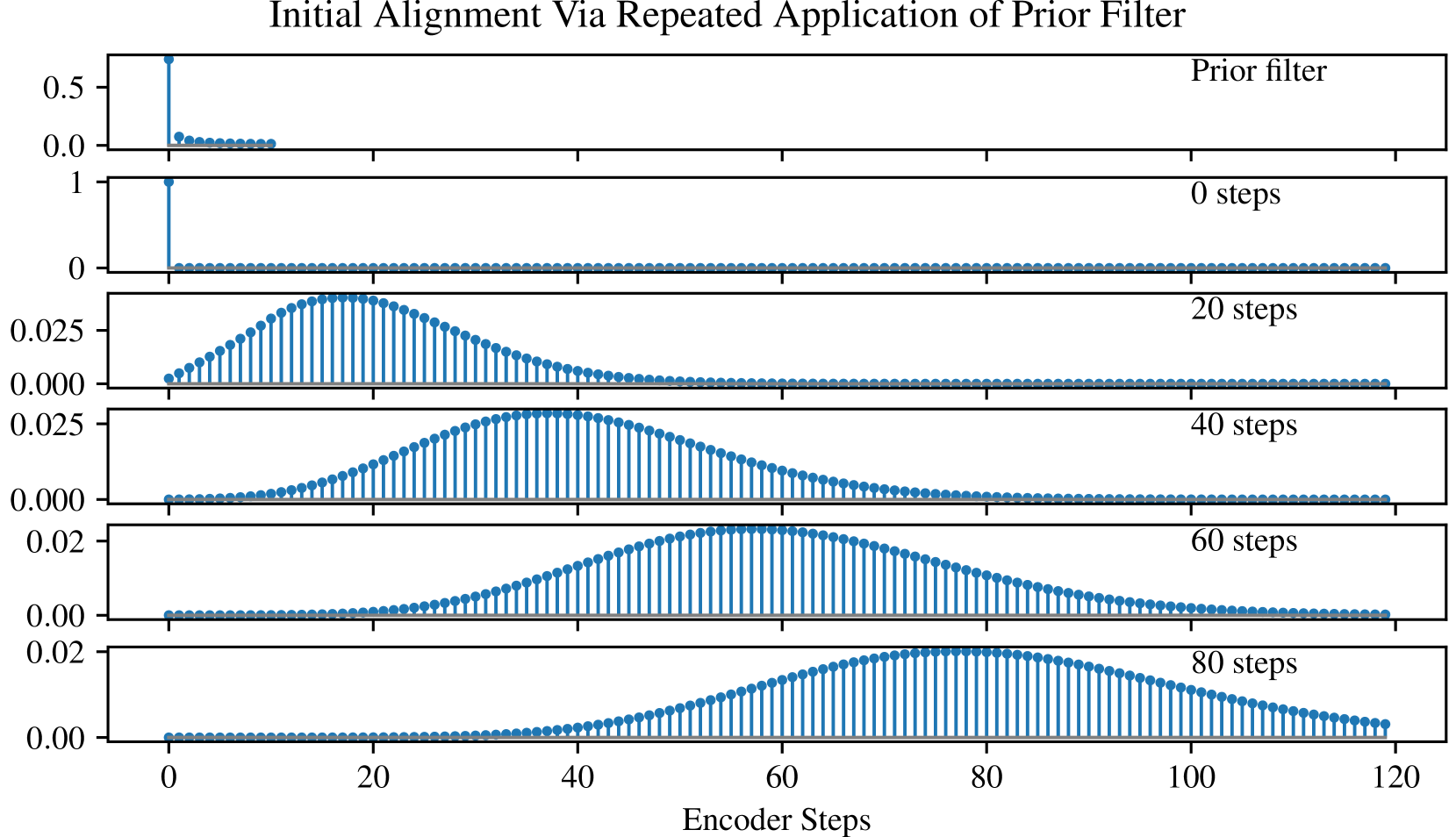
Figure 1: Initial alignment encouraged by the prior filter. (DCA, 2019)
이렇게 구성된 DCA는 다른 alignment 보다 빠르게 수렴하기 시작하고, 문장이 길어지더라도 오합성률이 크게 늘어나지 않는다.
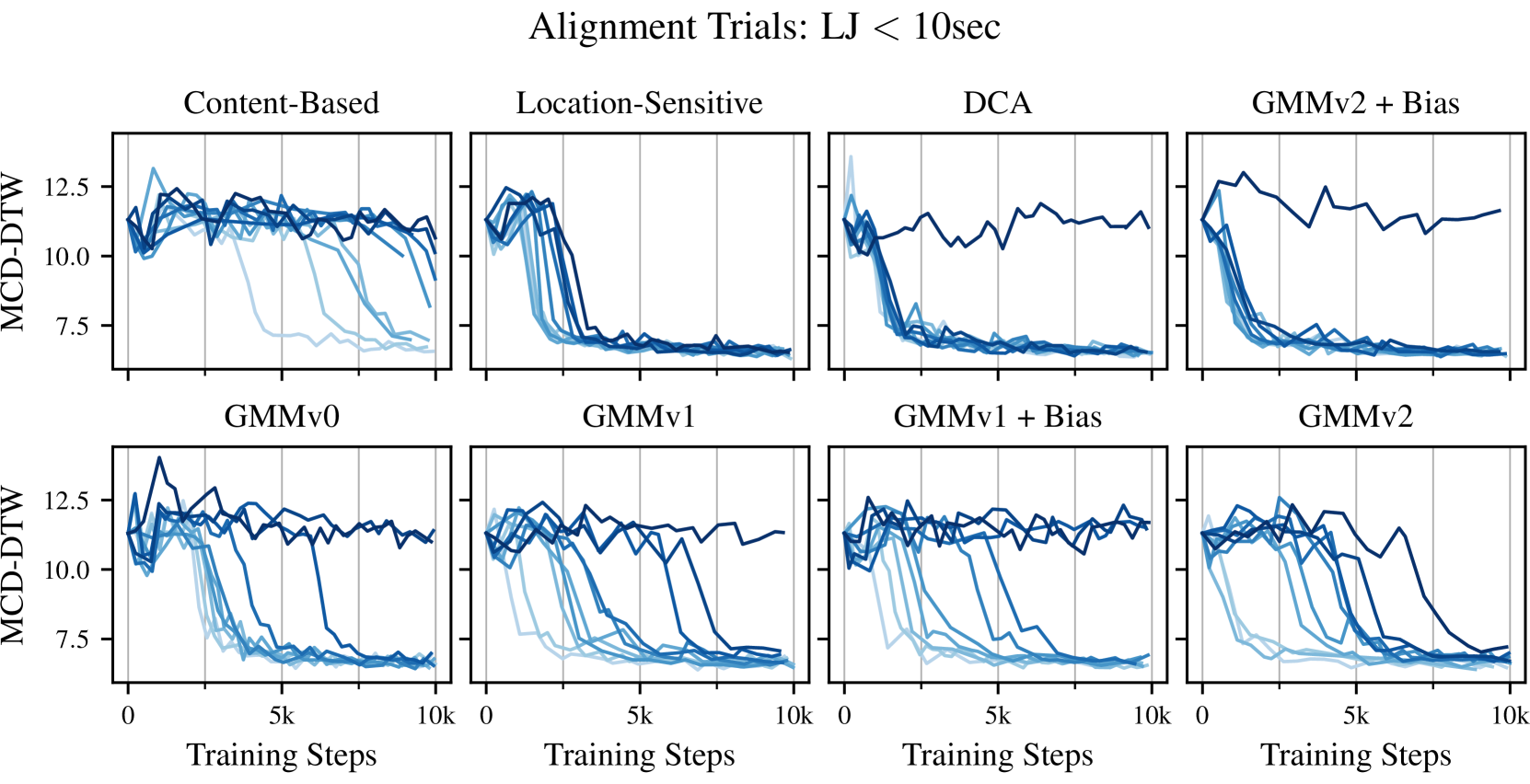
Figure 2: Alignment trials for 8 different mechanisms. (DCA, 2019)
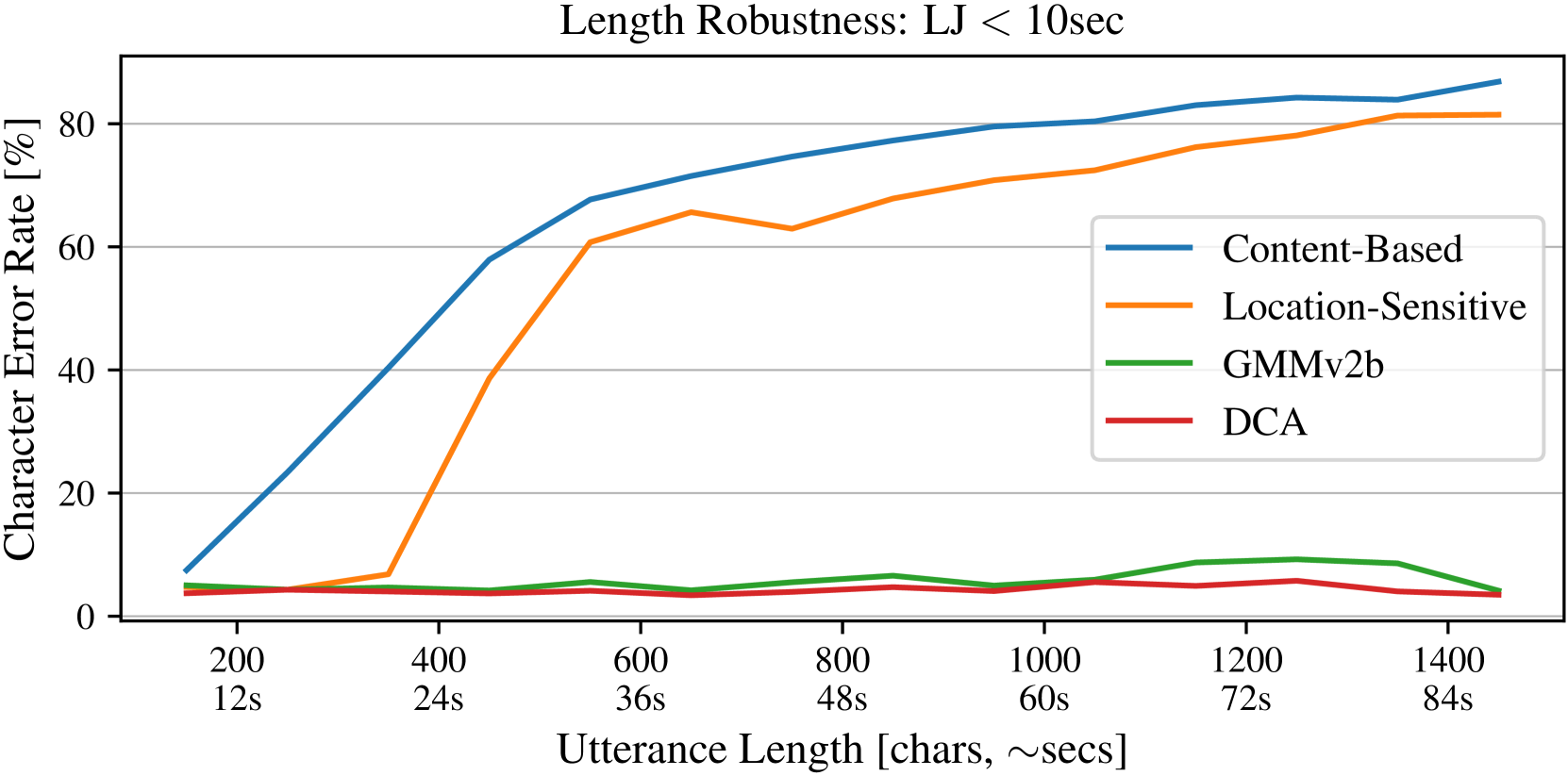
Figure 3: Utterance length robustness. (DCA, 2019)
Move to Parallel TTS
Autoregressive 모델은 꾸준히 발전해왔지만, 태생적으로 합성 속도와 alignment에 대한 engineering cost는 극복할 수 없다.
이에 연구자들은 다시금 발화 길이를 기반으로 forced align을 구성하는 것에 관심을 가지기 시작했고, 이렇게 개발된 것이 FastSpeech[arXiv:1905.09263]이다.
다음 글에서는 FastSpeech와 이후의 Parallel TTS에 관해 이야기 한다.
Reference
- A Survey on Neural Speech Synthesis, Tan et al., 2021. [arXiv:2106.15561]
- Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks, Graves et al., 2006.
- WaveNet: A Generative Model for Raw Audio, Oord et al., 2016. [arXiv:1609.03499]
- Tacotron: Towards End-to-End Speech Synthesis, Wang et al., 2017. [arXiv:1703.10135, git:keithito/tacotron, git:r9y9/tacotron_pytorch]
- Neural Machine Translation by Jointly Learning to Align and Translate, Bahdanau et al., 2014. [arXiv:1409.0473]
- Tacotron2: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions, Shen et al., 2017. [arXiv:1712.05884, git:NVIDIA/tacotron2]
- Attention-Based Models for Speech Recognition, Chorowski et al., 2015. [arXiv:1506.07503]
- DCTTS: Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention, Tachibana et al., 2017. [arXiv:1710.08969]
- TransformerTTS: Neural Speech Synthesis with Transformer Network, Li et al., 2019. [arXiv:1809.08895]- Forward Attention in Sequence-to-sequence Acoustic Modeling for Speech Synthesis, Zhang et al., 2018. [arXiv:1807.06736]
- Forward Attention in Sequence-to-sequence Acoustic Modeling for Speech Synthesis, Zhang et al., 2018. [arXiv:1807.06736]
- DCA: Location-Relative Attention Mechanisms For Robust Long-Form Speech Synthesis, Battenberg et al., 2019. [arXiv:1910.10288]
- WaveRNN: Efficient Neural Audio Synthesis, Kalchbrenner et al., 2018. [arXiv:1802.08435]
- LPCNet: Improving Neural Speech Synthesis Through Linear Prediction, Valin and Skoglund, 2018. [arXiv:1810.11846, git:xiph/LPCNet]
- MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis, Kumar et al., 2019. [arXiv:1910.06711, git:seungwonpark/melgan]
- FastSpeech: Fast, Robust and Controllable Text to Speech, Ren et al., 2019. [arXiv:1905.09263]
- g2p: English Grapheme To Phoneme Conversion, [git:Kyubyong/g2p]
- phonemizer: Simple text to phones converter for multiple languages, [git:bootphon/phonemizer]
- TTS: a deep learning toolkit for Text-to-Speech, battle-tested in research and production, [git:coqui-ai/TTS]