Research: AgentFuzz, Agentic Fuzzing Harness Generation with LLM
아래 글은 2024년 3월부터 11월까지 수행한 학부 졸업 프로젝트에 관한 수기이다.
- Research about the Automatic Fuzzing Harness Generation
- Keyword: Software Testing, Fuzzing, Harness Generation, Large Language Model, LLM
- Basis: How to increate Branch Coverage in fuzzing.
- Problem: Low TP Rate in Harness Generation with PromptFuzz.
- Solution: Agentic Harness Generation.
- Benefits: Improved Branch Coverage of the three projects; libxml2, libpcap, and libaom.
- Contribution: Suggest an LLM Agent for the Harness Generation.
- Weakness or Future work: -
Introduction
소프트웨어 테스팅에서 Fuzzing은 소프트웨어에 무작위 입력을 대입하여 결함의 발생 여부를 관찰하는 방법론을 일컫는다. 무작위 입력을 생성하여 소프트웨어에 대입하고, 결함의 관찰을 대행하는 도구를 Fuzzer라 지칭한다. 경우에 따라 완전히 무작위한 값을 생성하기도 하고, 사용자에 의해 주어진 입력을 활용하기도 한다.
일반적으로 무작위 값을 단순히 소프트웨어에 입력할 경우, 대다수는 인터페이스에 해당하는 영역에서 입력값 검증 등 조건 분기를 통과하지 못하고 조기에 종료된다. 이에 내부 구현에 해당하는 영역은 대개 실행되지 않고, 테스트의 범위는 좁아지게 된다. 테스트의 범위를 효과적으로 확장하기 위해서는 다양한 조건 분기를 관측 및 선택하여, 각 경로를 exhaustive하게 탐색하는 것이 유리하다.
분기의 탐색을 효과적으로 수행하기 위해 Fuzzer는 Coverage를 활용하기도 한다.
소프트웨어 테스팅에서는 소프트웨어의 동작 과정에서 어떤 코드 블럭/분기/함수 등이 몇 번 실행되었는지 기록하여, 이를 “Coverage"라는 이름으로 관리한다. 기존까지는 실행되지 않았던 새로운 코드 블럭/분기/함수가 실행된 경우, 우리는 Coverage가 증가하였다고 표현한다.
몇몇 Fuzzer는 Coverage를 증가시킨 입력에 높은 우선순위를 두고, 우선순위에 따라 과거의 입력을 선택하여 무작위로 변조-소프트웨어에 대입하는 일련의 작업을 반복한다. 이 경우 전략 없이 단순 무작위 입력값을 생성하는 Fuzzer에 비해 높은 확률로 Coverage가 증가하는 방향의 입력이 성생되길 기대할 수 있다.
이렇게 무작위로 값을 변조하는 과정을 Mutation이라 하고, 과거의 입력을 Seed Corpora(복수형 Seed corpus)라 하자. 또한 Coverage 기반의 Mutation 전략을 가지는 Fuzzer를 아래 수기에서는 Greybox Fuzzer라 표현하겠다.
Greybox Fuzzer 역시 한계를 가진다. Coverage 기반의 Mutation 전략을 통해 상대적으로 테스트 범위를 확장할 수 있었지만, 충분히 복잡한 소프트웨어의 분기 구조 속에서 무작위 입력만으로 도달할 수 있는 코드에는 한계가 있다. 또한, 그래픽 인터페이스를 내세운 소프트웨어의 경우, 생성된 입력을 적절한 인터페이스에 전달할 별도의 장치도 필요하다.
이러한 상황 속 더욱 효과적인 테스트를 위해 등장한 것이 Fuzzer Harness이다. Harness는 무작위 입력을 테스트 대상에 전달하는 별도의 소프트웨어로, 무작위 값을 인자로 특정 함수를 호출하거나, 네트워크 혹은 GUI 이벤트를 모방하여 무작위 입력을 인터페이스에 연결한다. Fuzzer는 Harness를 실행하고, Harness는 Fuzzer가 생성한 무작위 입력을 소프트웨어에 전달한다.
이를 통해 인터페이스의 제약에서 벗어나 테스트 대상의 특정 구현체를 직접 Fuzzing 할 수 있다.
다만, 이러한 Harness를 작성하기 위해서는 테스트 대상에 관한 이해가 선행되어야 하며, 테스트 대상에 새 기능이 추가 되거나 수정될 경우 Harness 역시 수정되어야 할 수 있다.
OSS-Fuzz-Gen, PromptFuzz 등 프로젝트는 이에 대응하기 위해 LLM을 활용하여 Harness를 생성, Fuzzing을 수행한다. Harness 작성 시간을 단축하고, Fuzzing의 진행 경과에 따라 동적으로 테스트가 부족한 영역에 Harness를 보강하여 전반적인 테스트 커버리지를 높여간다.
이번 졸업 프로젝트는 이러한 맥락 속에서 OSS-Fuzz-Gen과 PromptFuzz의 문제점을 정의하고, 그 개선점으로 AgentFuzz; Agentic fuzz harness generation을 제안한다.
Relative Works: OSS-Fuzz-Gen
OSS-Fuzz[google/oss-fuzz]는 구글에서 운영하는 오픈소스 Fuzzing 프로젝트이다. 오픈소스 제공자가 빌드 스크립트와 Fuzzer를 제공하면 구글이 ClusterFuzz[google/cluster-fuzz]를 통해 Google Cloud Platform(이하 GCP) 위에서 분산 Fuzzing을 구동-결과를 통고해 주는 방식으로 작동한다.
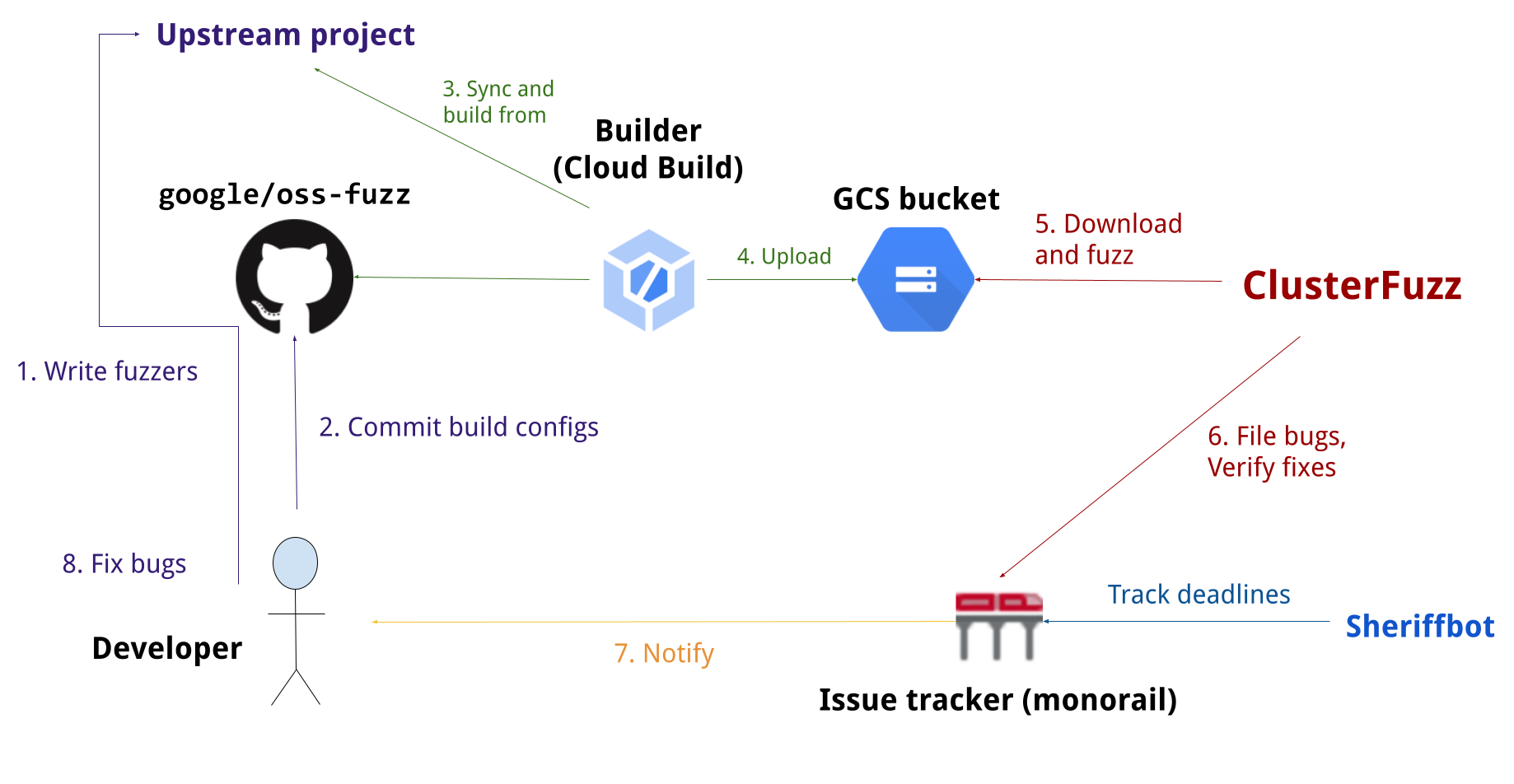
Figure 1. google/oss-fuzz#Overview
일부 오픈소스 프로젝트에 대해 OSS-Fuzz는 LLM 기반으로 Harness를 생성-테스트하는 일련의 파이프라인을 제공한다; OSS-Fuzz-Gen[google/oss-fuzz-gen].
OSS-Fuzz는 Fuzz-introspector[ossf/fuzz-introspector]를 통해 ClusterFuzz의 실행 결과로부터 어떤 함수가 얼마나 호출되었고, 어떤 분기에 의해 후속 함수의 호출이 불발되었는지 분석-전달한다(i.e. fuzz-blocker, Figure 2.). OSS-Fuzz-Gen은 테스트가 미진한(호출되지 않았거나, 테스트 범위에 포함되지 않은) 함수를 fuzz-introspector의 보고서로부터 발췌하여 LLM에게 해당 함수의 Harness 생성을 요청한다.
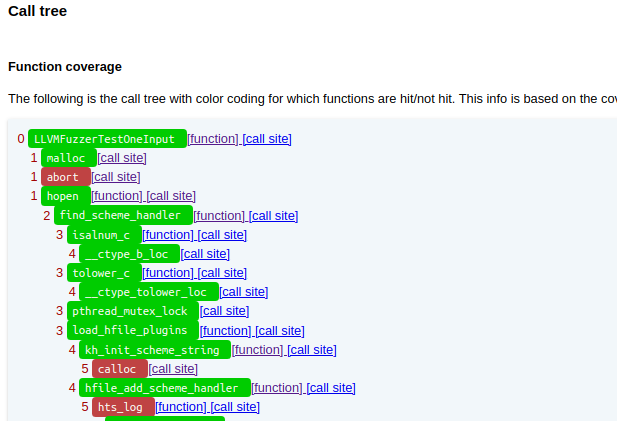
Figure 2. Reachability tree with coverage overlay (ref:git+ossf/fuzz-introspector)
e.g. Prompt (from:oss-fuzz-llm-targets-public):
You are a security testing engineer who wants to write a C++ program to execute all lines in a given function by defining and initialising its parameters in a suitable way before fuzzing the function through `LLVMFuzzerTestOneInput`.
Carefully study the function signature and its parameters, then follow the example problems and solutions to answer the final problem. YOU MUST call the function to fuzz in the solution.
Try as many variations of these inputs as possible. Do not use a random number generator such as `rand()`.
All variables used MUST be declared and initialized. Carefully make sure that the variable and argument types in your code match and compiles successfully. Add type casts to make types match.
You MUST call `CJSON_PUBLIC(cJSON_bool) cJSON_Compare(const cJSON *const a, const cJSON *const b, const cJSON_bool case_sensitive)` in your solution!
*SKIPPED*
Problem:
``
CJSON_PUBLIC(cJSON_bool) cJSON_Compare(const cJSON *const a, const cJSON *const b, const cJSON_bool case_sensitive)
``
Generated:
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#ifdef __cplusplus
extern "C" {
#endif
#include "../cJSON.h"
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size); /* required by C89 */
int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size)
{
cJSON *a = cJSON_Parse((const char*)data);
cJSON *b = cJSON_Parse((const char*)data);
if(a == NULL || b == NULL) return 0;
cJSON_Compare(a, b, 0);
cJSON_Compare(a, b, 1);
cJSON_Delete(a);
cJSON_Delete(b);
return 0;
}
#ifdef __cplusplus
}
#endif
LLM은 함수의 Spec을 입력으로 Harness를 작성한다(주로 OpenAI GPT, Google Gemini). 단번에 Syntax Error가 없는 Harness를 생성하기는 어려우므로, OSS-Fuzz-Gen은 컴파일 에러 메시지를 LLM에게 전달하여 오류 수정을 요구한다.
Given the following C program and its build error message, fix the code without affecting its functionality. First explain the reason, then output the whole fixed code.
If a function is missing, fix it by including the related libraries.
Code:
``
CJSON_PUBLIC(cJSON_bool) cJSON_Compare(const cJSON *const a, const cJSON *const b, const cJSON_bool case_sensitive)
``
Solution:
``
#include <stdlib.h>
/* *SKIPPED* */
``
Build error message:
/src/cjson/fuzzing/cjson_read_fuzzer.c:1:1: error: unknown type name 'CJSON_PUBLIC'
CJSON_PUBLIC(cJSON_bool) cJSON_Compare(const cJSON *const a, const cJSON *const b, const cJSON_bool case_sensitive)
^
/src/cjson/fuzzing/cjson_read_fuzzer.c:1:25: error: expected ';' after top level declarator
CJSON_PUBLIC(cJSON_bool) cJSON_Compare(const cJSON *const a, const cJSON *const b, const cJSON_bool case_sensitive)
^
;
Fixed code:
최대 3~5회까지 수정을 반복하여 Syntax Error를 수정하고, 컴파일에 성공한 경우 최초 시동을 통해 Harness가 Fuzzing과 무관히 Crash를 내는지 확인한다. Fuzzing 전부터 Crash가 발생한다면, 생성된 Harness를 활용하여 Fuzzing을 수행하는 것이 무의미할 것이다.
FYI. 끝내 Syntax Error 해결에 실패한 경우 해당 Harness는 폐기하고, LLM에게 새 Harness 합성을 요구한다.
정상 작동한 Harness는 ClusterFuzz로 전달되고, GCP 위에서 Fuzzer를 구동한다.
OSS-Fuzz-Gen은 LLM을 활용하여 tinyxml2 등 프로젝트에서 Test Coverage를 30%까지 추가 획득하였다고 이야기한다[googleblog].
Relative Works: PromptFuzz
OSS-Fuzz-Gen은 LLM을 기반으로 가용한 Harness를 생성할 수 있다는 점을 보였다. 하지만, 대개 함수 개개에 대한 Harness를 작성하기에, API 간의 유기 관계를 테스트하는 것에는 한계가 있다. 특히나 Internal State를 공유하고, 이에 따라 조건 분기를 취하는 라이브러리의 경우, 어떻게 API를 조합하느냐에 따라 trigging할 수 있는 코드 블럭의 부류가 달라질 수 있다.
PromptFuzz[arXiv:2312.17677, git+PromptFuzz/PromptFuzz]는 이에 대응하고자 여러 API를 하나의 Harness에서 동시에 호출하는 방식을 취하고, 어떤 API를 선택하는 것이 테스트에 유리할지 전략을 제시한다.
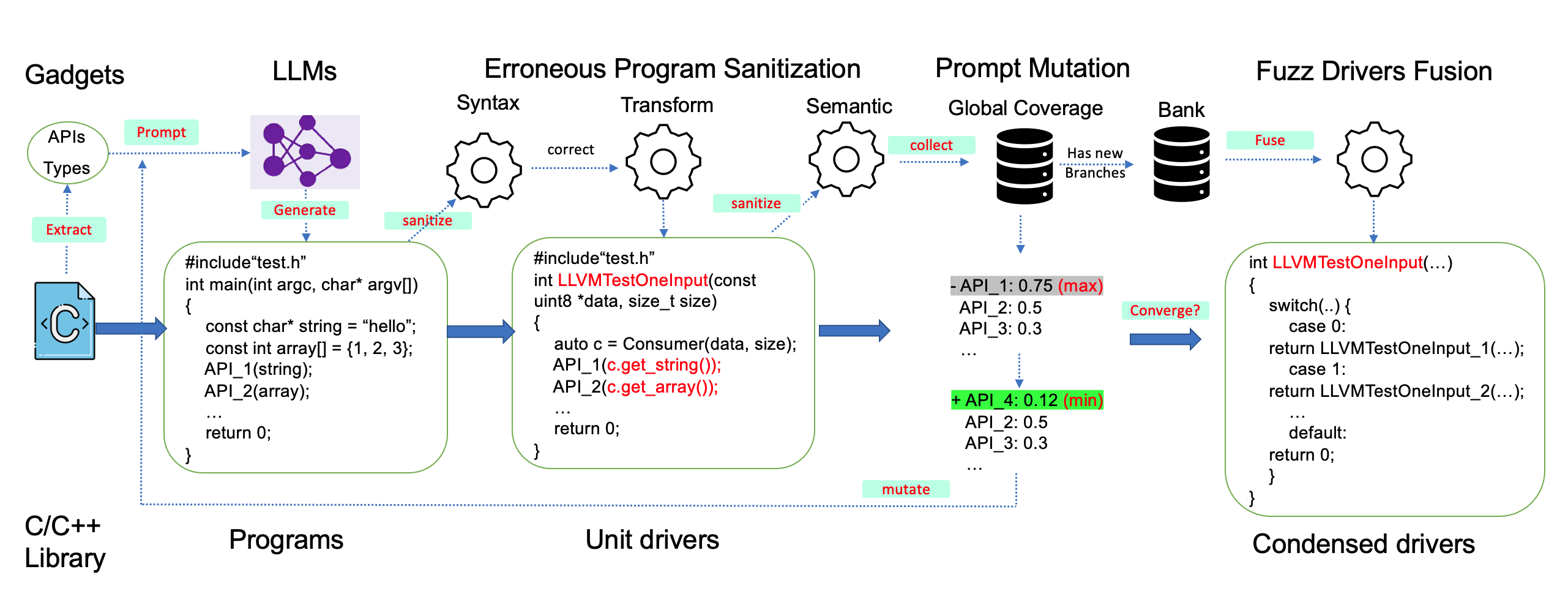
Figure 3. PromptFuzz/PromptFuzz#workflow
PromptFuzz는 라이브러리의 헤더 파일로부터 AST 파서를 활용해 함수(API) 및 타입의 선언을 발췌, Gadget이라는 이름으로 관리한다. PromptFuzz는 매 Round마다 이 중 일부를 선택하여 LLM에 Harness 생성을 요구한다.
PromptFuzz는 생성된 Harness의 유효성, Correctness를 검증하기 위한 몇 가지 방법론을 제안하며, 이를 모두 통과한 Harness에 대해서만 Fuzzing을 수행한다.
PromptFuzz: Harness Mutation
가장 먼저 고민한 문제는 어떤 API Gadget을 골라 Harness를 만드는가이다. PromptFuzz가 API의 유기 관계를 모델링하기 위해 선택한 방식은 상용 Fuzzer가 Seed Corpus를 Mutation 하는 정책과 동일 선상에 있다.
상용 Fuzzer는 유전 알고리즘을 통해 Coverage가 높은 Seed Corpora를 선택하고, 이를 무작위로 조작하여(random mutation을 가하여) 새로운 입력을 생성한다. Coverage를 측정하여 상위부터 Mutation을 수행하는 일련의 과정을 반복하며, Coverage를 높일 입력을 찾아나가는 것이다.
PromptFuzz는 API Gadget의 순열(이하 API Sequence)을 잘 선택하여 Harness를 구성, 테스트 범위를 확장하길 바란다. 그렇기에 API Sequence를 평가할 지표를 두어 서로 다른 API Sequence 사이에 순서를 정하고, 상위 API Sequence부터 Random Mutation을 수행하여 LLM에게 Harness 생성을 요청한다.
## PSEUDO CODE OF PROMPTFUZZ
type APISequence = list[APIGadget]
def round(seed_harnesses: list[Harness]):
# selection
selected: Harness = weighted_sample(
seed_harnesses,
weight_fn=quality_measure,
)
# mutation
new_api_sequence: APISequence = mutation(selected)
# generate to harness
harness: Harness = LLM(
SYSTEM_PROMPT,
f"Generate a fuzzer harness containing the given APIs: {new_api_sequence}",
)
# validation
if not is_valid(harness):
return ValidationFailureError()
# run the fuzzer
result = run_fuzzer(harness)
# append to seeds
seed_harnesses.append(harness)
return result
seed_harnesses, quiet = [], 0
# given
max_round: int
max_budget: float
max_quiet: int
# run the PromptFuzz
for _ in range(max_round):
result = round(seed_harnesses)
# terminal condition#1: API Budget
if litellm._current_cost > max_budget:
break
# terminal condition#2: Quiet round
if not isinstance(result, ValidationFailureError):
quiet = 0
elif quiet > max_quiet:
break
else:
quiet += 1
PromptFuzz는 Harness 역시 Mutation의 대상으로 바라보아 전략적으로 테스트 범위 확장을 의도한다.
Greybox Fuzzer가 Coverage를 Seed Corpus 평가의 지표로 두었다면, PromptFuzz는 API Sequence에 대해 Quality라는 지표를 제안한다.
Measure
Quality는 Density와 #Unique Branches의 곱으로 표현된다. Harness Mutation의 목표는 Coverage 확보이다. Mutated Harness를 통해 Coverage(혹은 #Unique Branches)가 얼마나 확보되었는지 파악하는 것은 자명한 일이다. 여기서 중요한 것은 Density의 역할이다.
FYI. #Unique Branches는 Harness를 단위 시간 동안 Fuzzing 하였을 때, Harness에 의해 실행된 대상 프로젝트 내 분기의 수이다. 대상 프로젝트의 Coverage는 #Unique Branches를 프로젝트 내 전체 분기의 수로 나눈 것과 같다.
$$\mathrm{Quality}(g) = \mathrm{Density}(g) \times (1 + \mathrm{UniqueBranches}(g))$$
PromptFuzz는 Harness 내 API의 유기 관계를 적극 활용하여 Coverage를 높이고자 한다. API의 유기 관계에 대한 평가 지표가 제안되어야 하고, 해당 지표가 Coverage 확보에 기여함을 보인다면 명쾌할 것이다.
PromptFuzz가 이를 위해 제안한 지표가 Density이다. API의 유기 관계는 앞선 API의 호출이 후속 API의 실행 흐름에 얼마나 영향을 미치는지로 표현된다. 한 API의 호출이 다른 API의 실행 흐름에 영향을 주기 위해서는 (1) 앞선 호출이 프로젝트의 State를 변화시켜, 후속 실행 흐름에 간접적 영향을 주거나 (2) 앞선 호출의 결과값이 후속 API의 인자로 전달되어 직접적 영향을 주는 2가지 경우로 나뉠 것이다.
Density는 이중 후자의 경우에 집중한다. Harness 내에 존재하는 API를 Node로 표현하고, Taint Analysis를 통해 Harness의 실행 흐름 중 한 API의 반환값이 다른 API의 인자로 전달되는 경우를 Directed Edge로 하여 API Call Depedency Graph를 그린다.
만약 아래의 Harness가 있다면, 다음의 CDG를 예상해 볼 수 있다.
vpx_codec_dec_cfg_t dec_cfg = {0};
...
// Initialize the decoder
vpx_codec_ctx_t decoder;
vpx_codec_iface_t *decoder_iface = vpx_codec_vp8_dx();
vpx_codec_err_t decoder_init_res = vpx_codec_dec_init_ver(
&decoder, decoder_iface, &dec_cfg, 0, VPX_DECODER_ABI_VERSION);
if (decoder_init_res != VPX_CODEC_OK) {
return 0;
}
// Process the input data
vpx_codec_err_t decode_res = vpx_codec_decode(&decoder, data, size, NULL, 0);
if (decode_res != VPX_CODEC_OK) {
vpx_codec_destroy(&decoder);
return 0;
}
// Get the decoded frame
vpx_image_t *img = NULL;
vpx_codec_iter_t iter = NULL;
while ((img = vpx_codec_get_frame(&decoder, &iter)) != NULL) {
// Process the frame
vpx_img_flip(img);
...
}
// Cleanup
vpx_codec_destroy(&decoder);
return 0;
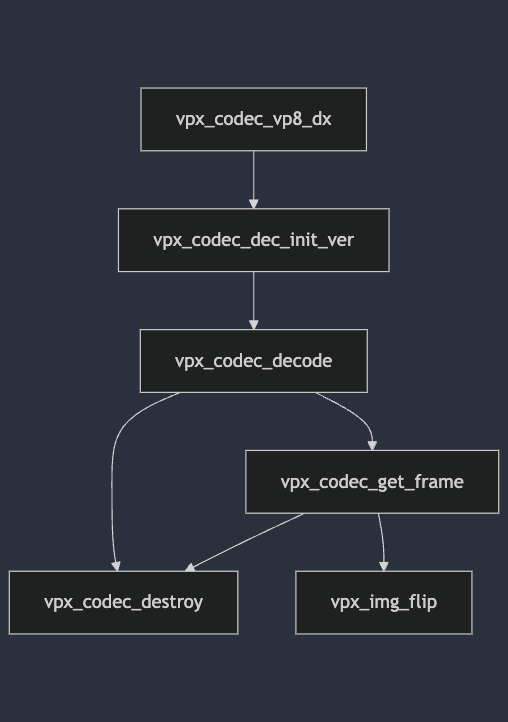
Figure 4. Call Dependency Graph
FYI. 위는 예시이며, 실제 구현과는 다를 수 있다.
Graph는 SCC로 분해가능하고, 각 Component의 Cardinality(집합 내 원소의 수) 중 가장 큰 값을 Density라 명명한다.
FYI. SCC(Strongly Connected Component): 노드의 집합, (1) 집합 내 어떤 임의의 두 노드를 선택하여도 이를 잇는 경로가 존재하고-Strongly Connected, (2) Graph 내 어떤 두 노드가 Strongly Connected이면 둘은 같은 SCC에 속함-Component. (Strongly Connected Nodes의 집합 중 가장 크기가 큰 집합.)
FYI. Graph는 SCC로 Partition 가능하다. (i.e. Graph는 SCC의 집합으로 표현 가능하고, Graph 내 모든 SCC는 mutually disjoint이다.)
위 CDG는 기재된 모든 함수 사이에 서로를 잇는 Edge가 존재하므로 Graph 전체가 하나의 SCC이며, Density는 SCC 내 노드의 개수인 6이다.
Density는 Harness 내 직접적 영향을 주고 받는 API의 군집 중 가장 큰 군집의 크기를 의미한다. Density가 크다는 것은 Harness 내의 API 유기 관계에 부피감이 있음을 의미한다. (1) 이는 너비를 의미할 수도 있고-여러 API의 독립적 실행 결과가 하나의 API에 영향을 가함, (2) 깊이를 의미할 수도 있으며-API의 호출이 순차적으로 영향을 가함, (3) 이 둘 모두를 의미할 수도 있다.
Density는 Taint Analysis의 범위에 따라 간접 영향에 관하여는 모델링하지 못할 수도 있고, 그 부피감이 어떤 형태의 Call Dependency를 가지는지 묘사하지 못하기도 한다.
결국 Quality는 (1) Coverage가 높을수록 (2) API의 유기 관계에 부피감이 있을수록 좋은 Harness라 정의하고 있다.
Mutation
Quality에 따라 Harness가 선택되고 나면 PromptFuzz는 Mutation을 수행한다. Byte string을 직접 조작하는 Corpus Mutation과 달리, Harness Mutation은 API Sequence 수준에서 Mutation을 가하고, LLM을 통해 Mutated API Sequence를 새로운 Harness로 생성하는 과정을 거친다.
$$\mathrm{Harness} \mapsto \mathrm{API\ Sequence} \mapsto \mathrm{Mutated} \mapsto \mathrm{New\ Harness}$$
LLM이 Mutated API Sequence를 토대로 Harness를 만들어도, 제시된 API가 모두 Harness에 포함되어 있지는 않다(LLM의 한계). 따라서 Harness에서 사용한 API를 모두 발췌하여 실행 순서에 따라 Topological Sort를 수행, 생성된 Harness의 API Sequence로 정의한다.
API Sequence에는 (1) API Insert, (2) API Remove, (3) Crossover 3가지 방식의 Mutation 중 하나를 무작위 선택하여 가하게 된다.
API Insert와 Remove는 주어진 API Sequence의 임의 지점에 새로운 API Gadget을 삽입하거나, 임의 지점의 API Gadget을 제거하는 방식으로 작동한다. Crossover는 또 다른 API Sequence와 임의 지점에서 Sequence 전-후반을 접합하는 방식으로 작동한다.
## PSEUDO CODE OF MUTATION
def insert(harness: Harness, gadgets: list[APIGadget]):
seq: APISequence = extract_apis(harness)
while True:
api: APIGadget = weighted_sample(
gadgets,
weight_fn=energy_measure,
)
if api not in seq:
break
seq.insert(random.randint(0, len(seq)), api)
return seq
def remove(harness: Harness):
seq: APISequence = extract_apis(hanress)
# inverse energy order
api: APIGadget = weighted_sample(
seq,
weight_fn=lambda x: 1 / energy_measure(x),
)
seq.remove(api)
return seq
def crossover(harness: Harness, seed_harnesses: list[Harness]):
seq: APISequence = extract_apis(harness)
other: Harness = weighted_sample(
seed_harnesses,
weight_fn=quality_measure,
)
other_seq: APISequence = extract_apis(other)
i = random.randint(1, len(seq) - 1)
j = random.randint(1, len(other_seq) - 1)
return seq[:i] + other_seq[j:]
new_api_sequence: APISequence
match random.randint(0, 2):
case 0: new_api_sequence = insert(harness, gadgets)
case 1: new_api_sequence = remove(harness)
case 2: new_api_sequence = crossover(harness, seed_harnesses)
return new_api_sequence
Crossover는 역시 Quality에 따라 Harness를 추가 선발하여 활용한다. 동일 논리라면, Insert와 Remove 역시 추가 혹은 제거 대상으로 삼을 API의 기준이 필요할 것이다.
프로젝트에 따라 PromptFuzz에서 발췌된 API Gadget은 만여개 단위까지 늘어난다. 이 중에는 실제로도 자주 쓰이는 API로, LLM 역시 단번에 활용처를 이해하고 컴파일까지 성공하는 API가 있는반면, 자주 쓰이지 않아 LLM 역시 컴파일에 실패하거나 빈번히 오사용하는 API도 있다.
PromptFuzz는 이러한 상황에서 이미 충분히 테스트 되었다 판단된 API의 사용을 줄이고, 테스트 되지 않은 API의 사용 시도를 늘리기 위해 Insert와 Remove의 대상에 Energy라는 기준을 제시한다.
$$\mathrm{Energy}(a) = \frac{1 - \mathrm{Coverage}(a)}{(1 + \mathrm{Seed}(a))^E \times (1 + \mathrm{Prompt}(a))^E}$$
Energy는 각 API에 대한 평가 지표로, Energy가 높을수록 Mutation 후 Harness에 해당 API가 잔존할 확률을 높이고, Energy가 낮을수록 잔존 확률을 낮춘다.
FYI. Coverage(a)는 API $a$ 내부의 분기 중 실행된 분기의 비율. Prompt(a)는 mutated api sequence에 API $a$가 포함된 횟수(LLM에게 전달된 횟수). Seed(a)는 실제 API $a$를 포함하고 있는 Seed Harnesses의 수(API가 LLM에게 합성 요청되어도 실제 Harness에 포함되지 않을 수 있고, 포함되더라도 Validation 단계를 통과하지 못해 Seed Harnesses에 포함되지 않을 수 있음.)
FYI. E는 하이퍼파라미터, git+PromptFuzz/PromptFuzz는 1로 가정.
API가 충분히 테스트 되었다 판단될수록(i.e. Coverage가 100%에 가까워질수록) API는 Mutated Harness에 포함될 가능성이 줄어든다. 이는 자명하다.
어떤 API는 LLM에게 많이 합성 요청되었지만, 컴파일 오류나 오사용으로 인해 Fuzzing 대상이 되지 못할 수 있다. 이 경우는 LLM의 성능상 한계라 이해하고, Energy를 통해 해당 API 역시 Mutated Harness에 포함될 가능성을 낮춘다.
결국 PromptFuzz는 Quality와 Energy를 통해 API가 고루 테스트 될 수 있도록 하고, 지표 기반 Mutation으로 좋은 Harness를 찾아나간다.
PromptFuzz: Harness Validation
생성된 Harness는 유효성, Correctness를 검증받게 된다. Syntax Error를 포함하여 컴파일이 불가능하거나, API의 오사용으로 인해 새로이 탐색 가능한 분기가 없다면 굳이 이를 구동할 이유가 없을 것이다. PromptFuzz는 효과적인 Fuzzing을 위해 몇 가지 검증 기준을 제안한다.
가장 간단히는 컴파일이 가능해야 한다. LLM의 응답으로부터 ```의 코드 블록이 존재한다면, 블록 내에서 코드를 발췌-컴파일을 시도한다. Syntax Error가 발생할 경우 LLM에게 오류 수정을 요구하는 OSS-Fuzz-Gen과 달리 PromptFuzz는 곧장 생성된 Harness를 폐기하고, 새로 생성을 시도한다.
컴파일에 성공했다면, 최대 10분간 Fuzzer를 구동한다. 1분 단위로 현재 Fuzzer의 Coverage를 측정하여, Coverage가 증가할 경우 지속-유지될 경우 구동을 중지한다. 이후 기존까지 실행되었던 Seed Harnesses의 Fuzzing 결과와 비교하여 새로운 분기가 발견되었는지 검사한다. 만약 분기가 발견되지 않았다면, 현재 검토 중인 Harness는 Coverage 확보에 기여하기 어렵다 판단하여 폐기한다.
만약 컴파일에도 성공하고, 새로운 분기도 확인하였다면 Critical Path 검증으로 마무리 한다.
Critical Path
Critical Path는 Harness 내 여러 Control Flow 중 가장 많은 API를 호출할 수 있는 흐름을 의미한다. 예를 들면, Figure 4.의 예시에서 Critical Path는 다음 6개 API를 포함하고 있다.
vpx_codec_vp8_dx > vpx_codec_dec_init_ver > vpx_codec_decode > vpx_codec_get_frame > vpx_img_flip > vpx_codec_destroy
PromtpFuzz는 최대 10분간의 Harness 구동 중 Critical Path 내의 모든 API가 Hit 되었는지 검사한다.
만약 생성된 Harness가 API를 오사용하였다면 테스트는 비정상 종료될 것이고, Harness에 포함된 API 중 일부는 실행되지 않을 것이다. 반대로 모든 API가 사용되었는지를 테스트한다면, 주류 흐름 외의 에러 핸들링에 사용되는 API까지 강제되는 등 통과가 불가능하거나 비효율적인 평가가 이뤄질 수 있다.
이에 PromptFuzz는 주류 API 흐름의 실행을 보장하고자 Critical Path를 정의하고, 주류 흐름 내의 모든 API가 실행되었는지를 검토한다.
PromptFuzz: Benchmarks
PromptFuzz는 총 14개 프로젝트에 대해 벤치마크 테스트를 수행한다.
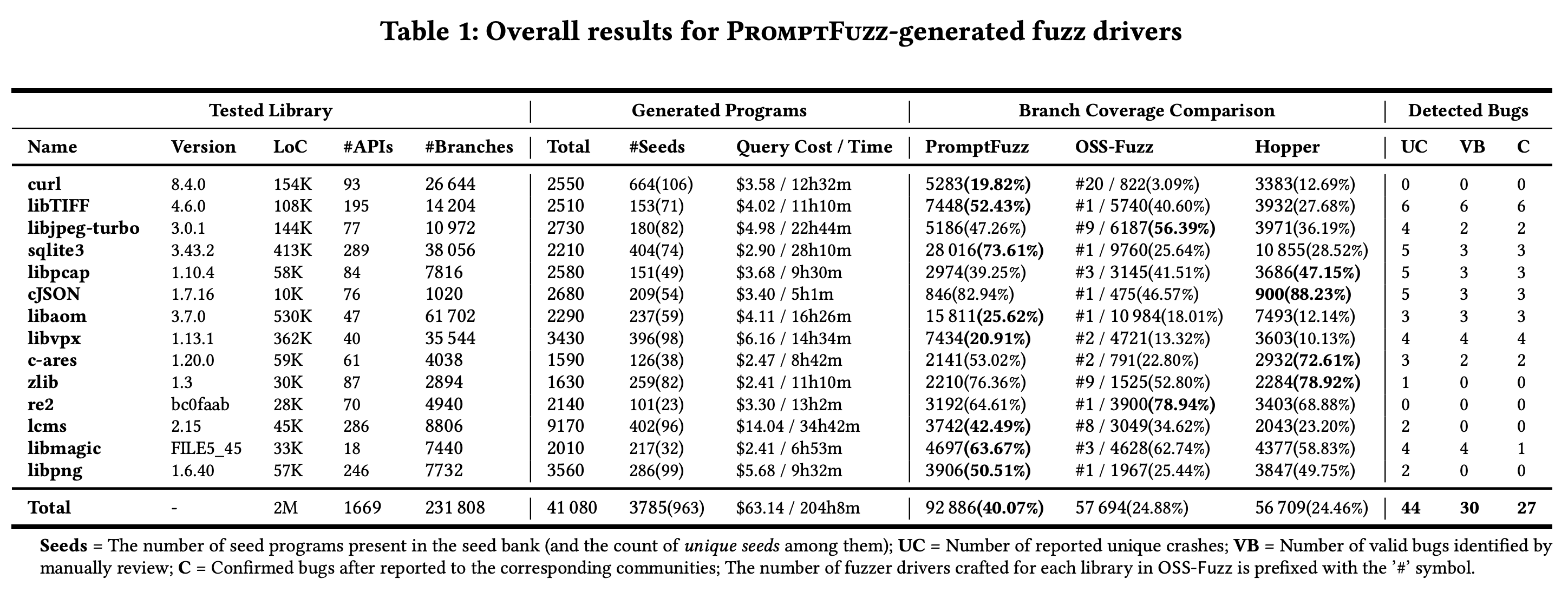
Table 1. Overall results for PromptFuzz-generated fuzz drivers
AgentFuzz의 개발 전, git+PromptFuzz/PromptFuzz를 토대로 벤치마크 테스트를 재현하였다. 논문에서 Harness 생성에 사용한 gpt-3.5-turbo-0613 모델은 현재 Deprecate 되어 사용이 불가능하다. 아래는 gpt-4o-mini-2024-07-18을 운용하였을 때의 결과를 첨부한다.
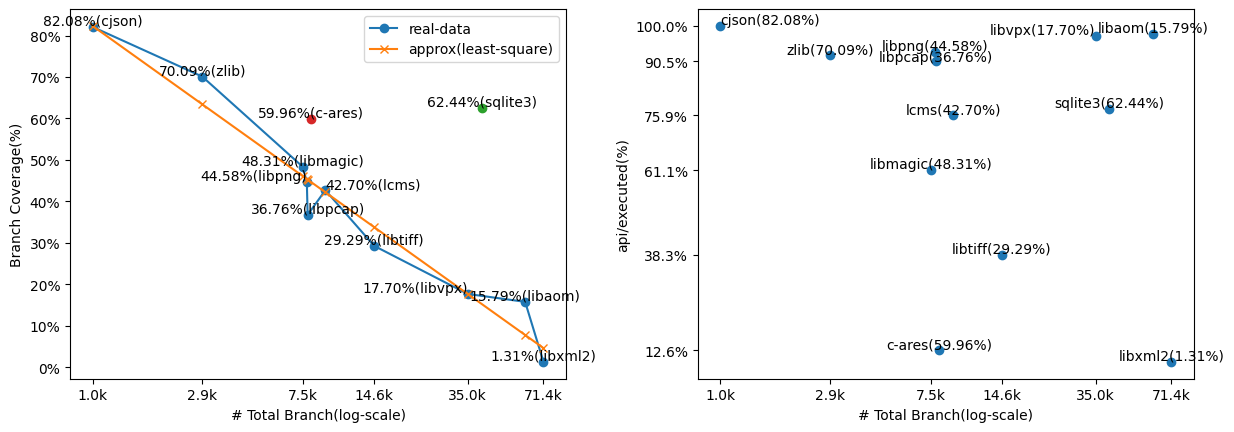
Figure 5. Evaluation results of the benchmark projects.
프로젝트의 Branch Coverage는 대개 프로젝트의 전체 Branch 수(i.e. # Total Branch, log-scale)와, 전체 API Gadget 중 실행된 API의 비율(i.e. api/executed, %)에 상관관계를 갖는다. 이 둘은 직관 상 자명한 지표이다.
(1) 일정 깊이 이상의 경로를 Random mutation만으로 접근하게 될 가능성은 깊이에 따라 기하급수적으로 감소한다. Branch가 많아지면 Nested Branch의 존재 가능성이 커지고, 자연스레 Mutation의 한계로 Branch Coverage가 감소하는 것이다.
(2) AgentFuzz는 거의 모든 API를 LLM에게 1회 이상 전달한다. 하지만 LLM의 성능상 한계로 인해, 생성된 Harness가 요청된 API 중 일부를 포함하지 않거나, 포함하더라도 평가를 통과하지 못해 결국 테스트 되지 않는 API가 발생한다. 해당 API에 포함된 Branch는 실행 기회를 얻지 못하고, Branch Coverage에는 상한선이 발생한다.
| proj#revision | Branch Cov | Total Branch | Executed API | Exposed API | Coverage(R/UB) |
|---|---|---|---|---|---|
| cjson#424ce4c | 82.08% | 1038 | 100% | 67.85% | 82.08% |
| zlib#545f194 | 70.09% | 2906 | 92.04% | 57.89% | 83.12% |
| c-ares#3b8058 | 59.96% | 8076 | 12.59% | 17.44% | 76.67% |
| sqlite3#27095f | 62.44% | 39926 | 77.66% | 10.66% | 91.93% |
| libpng#d3cf9b | 44.58% | 7750 | 93.08% | 47.49% | 52.31% |
| libmagic#cf6bf1 | 48.31% | 7470 | 61.11% | 5.84% | 163.51% |
| libpcap(1.11.0) | 36.76% | 7808 | 90.47% | 15.30% | 36.90% |
| lcms#5c54a6 | 42.70% | 9220 | 75.94% | 24.31% | 63.10% |
| libtiff#7a3fb2 | 29.29% | 14576 | 38.26% | 21.77% | 155.42% |
| libvpx#b15d2a | 17.70% | 35050 | 97.29% | 0.88% | 20.35% |
| libaom#47f42d | 15.79% | 60100 | 97.87% | 0.48% | 15.87% |
| libxml2(2.9.4) | 1.31% | 71378 | 9.41% | 54.32% | 7.06% |
이를 기반으로 성능 분석과 개선점 확보를 위해 다음과 같이 분류해 보았다.
- Executed API 비율 70% 미만: c-ares(59.96%), libmagic(48.31%), libtiff(29.29%), libxml2(1.31%)
- 상한 대비 Coverage 70% 미만
- API 노출 비율 10% 미만: libvpx(17.70%), libaom(15.79%)
- 원인 불명: libpng(52.31%), libpcap(36.90%)
- lcms(42.70%): 다소 못 미치지만, 다른 프로젝트에 비해 비교적 양호한 Coverage를 확보
- Executed API 비율 70% 이상, 상한 대비 Coverage 70% 이상: cjson(82.08%), zlib(70.09%), sqlite3(62.44%)
FYI. Executed API: 전체 API Gadget 중 실행이 확인된 API의 비율 (i.e. api/executed, %)
FYI. 상한 대비 Coverage(R/UB; Relative coverage to upper bound): 실행된 API의 전체 Branch 모수 대비 실행된 Branch의 비율(실행되지 않은 API의 Branch는 모수에서 제외).
Executed API의 비율이 70% 미만인 네 개 프로젝트(c-ares 12.59%, libmagic 61.11%, libtiff 38.26%, libxml2 9.41%)는 Branch Coverage가 60% 미만이다. 이는 생성된 Harness가 API를 충분히 포함하지 않아, Coverage 확보에 불리한 조건을 가지고 시작하는 사례이다.
Coverage(R/UB)의 관찰 목적은 LLM이 만든 Harness가 API Gadget을 충분히 포함한다면, 이후 Branch Coverage 확보에 문제가 없는지 확인하기 위함이다. Nested Branch가 유독 많거나, Branch의 조건이 tight 한 경우에는 많은 API가 테스트 되어도 Random Mutation 등의 한계로 여전히 Branch Coverage 확보가 어려울 수 있다.
실제로 상한 대비 Coverage가 70% 미만인 프로젝트는 총 6건이 관찰되었다. 이중 libvpx와 libaom은 비디오 코덱 라이브러리로, 입력에 따라 어떤 코덱 모듈이 실행될지 결정된다. Public corpus에 특정 코덱이 주어지지 않거나, 운이 좋게 변조된 입력이 다른 코덱으로 인식되어도, 후속 파싱 과정에서 sanity check failure로 조기 종료될 가능성이 높다.
이러한 사례들은 라이브러리에 존재하는 전체 함수의 수 대비 API로 공개된 함수의 수가 10% 미만이다(이하 Exposed API, %).
원인 불명의 두 개 라이브러리 libpng와 libpcap을 제외하면 나머지는 Executed API의 비율 70% 이상, 상한 대비 Coverage(R/UB) 역시 70% 이상으로 양호한 경향을 보인다.
TP Rate and Executed API
다음은 12개 프로젝트, 40회의 실험에 대한 Pearson Correlation Matrix이다.
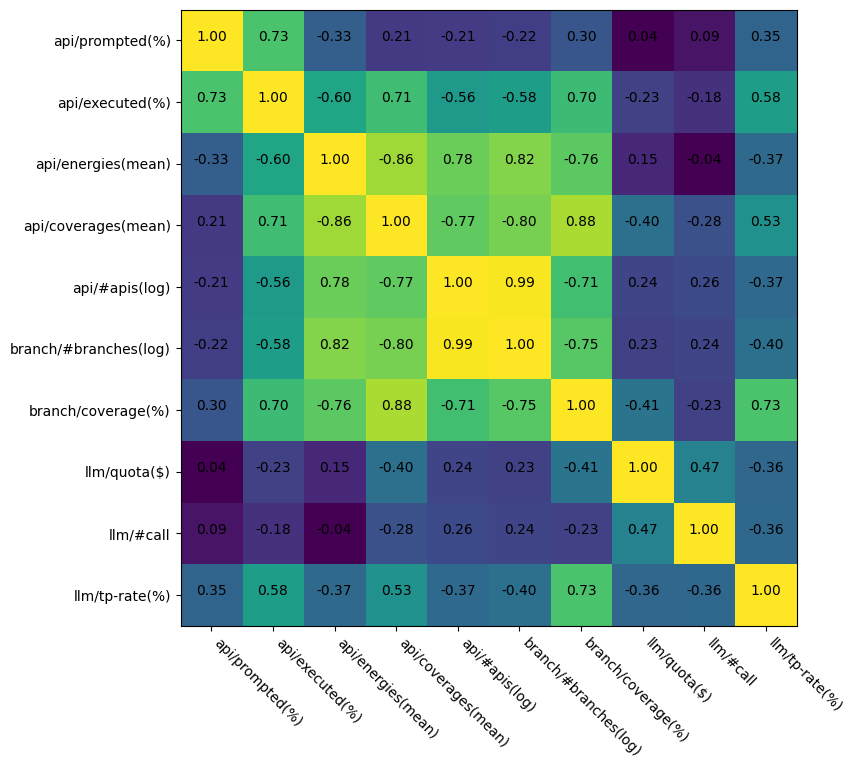
Figure 6. Matrix of Pearson Correlation
항목 설명
이번 AgentFuzz 프로젝트는 Branch Coverage 확보를 대전제로 잡는다.
Branch Coverage(i.e. branch/coverage, %)와 다른 지표의 상관관계를 살피면, 다음의 순서대로 계수가 높은 것을 확인할 수 있다.
- (절댓값 기준) api/coverages(mean) 0.88 > api/energies(mean) 0.76 > branch/#branches(log) 0.75 > llm/tp-rate(%) 0.73 > api/#apis(log) 0.71 > api/executed(%) 0.70
이중 api/coverages(mean)과 api/energies(mean)은 직접적으로 Branch Coverage와 포함 관계를 가지는 지표이기에 제외, branch/#branches(log)와 api/#apis(log)는 프로젝트와 함께 주어지는 수치이므로 제외한다.
현재 관찰된 지표 내에서 0.70 이상의 계수를 가지며, 개선의 대상으로 삼을 수 있는 지표는 TP Rate와 Executed API의 비율이다.
앞서 확인하였듯, Executed API는 직접적으로 Branch Coverage와 인과 관계를 가지는 지표이며, 12개의 프로젝트 중 4개의 프로젝트는 70% 미만의 Executed API를 가진다. 이는 특히 libxml2에서 그 문제가 두드러진다(Executed API 9.41%).
Executed API를 개선할 수 있다면, 확보 가능한 Branch Coverage의 상한을 높이는 일이 될 것이다.
Q. 정말 대부분의 API가 LLM에게 전달되었는가
Executed API를 살피기 전, 정말 대부분의 API가 LLM에 전달되었는지 확인해야 한다. 만약 LLM에 API가 전달되지 않았다면, Execution은 당연히 기대할 수 없다.
| proj#revision | Total API | Prompted API | Executed API | Executed/Prompted (%) |
|---|---|---|---|---|
| cjson#424ce4c | 76 | 76(100%) | 76(100%) | 100% |
| zlib#545f194 | 88 | 87(98.86%) | 81(92.04%) | 93.10% |
| c-ares#3b8058 | 135 | 135(100%) | 17(12.59%) | 12.59% |
| sqlite3#27095f | 291 | 290(99.65%) | 226(77.66%) | 77.93% |
| libpng#d3cf9b | 246 | 246(100%) | 229(93.08%) | 93.08% |
| libmagic#cf6bf1 | 18 | 18(100%) | 11(61.11%) | 61.11% |
| libpcap(1.11.0) | 84 | 83(98.80%) | 76(90.47%) | 91.56% |
| lcms#5c54a6 | 291 | 287(98.62%) | 221(75.94%) | 77.00% |
| libtiff#7a3fb2 | 196 | 193(98.46%) | 75(38.26%) | 38.86% |
| libvpx#b15d2a | 37 | 37(100%) | 36(97.29%) | 97.29% |
| libaom#47f42d | 47 | 45(95.74%) | 46(97.87%) | 97.82% |
| libxml2(2.9.4) | 1594 | 1109(69.57%) | 150(9.41%) | 13.52% |
확인 결과 libxml2를 제외한 11개 프로젝트는 모두 95% 이상의 API가 LLM에게 전달되었다. libxml2 역시 70%에 가까운 API가 LLM에게 전달되었으나, 전달된 API 중 13.52%만이 실제 TP Harness에 1회 이상 포함되었다.
앞서 Executed API의 비중이 70%를 넘지 않았던 c-ares, libmagic, libtiff, libxml2는 Prompted API 대비 Executed API의 비율이 역시 70%를 넘지 않았다.
이는 반대로 API Gadget이 1천여개를 넘지 않는다면, gpt-4o-mini 기준 5$의 budget 내에서 현재의 Harness Mutation이 만드는 조합이 전체 API를 1회 이상 테스트하는데 충분함을 의미한다.
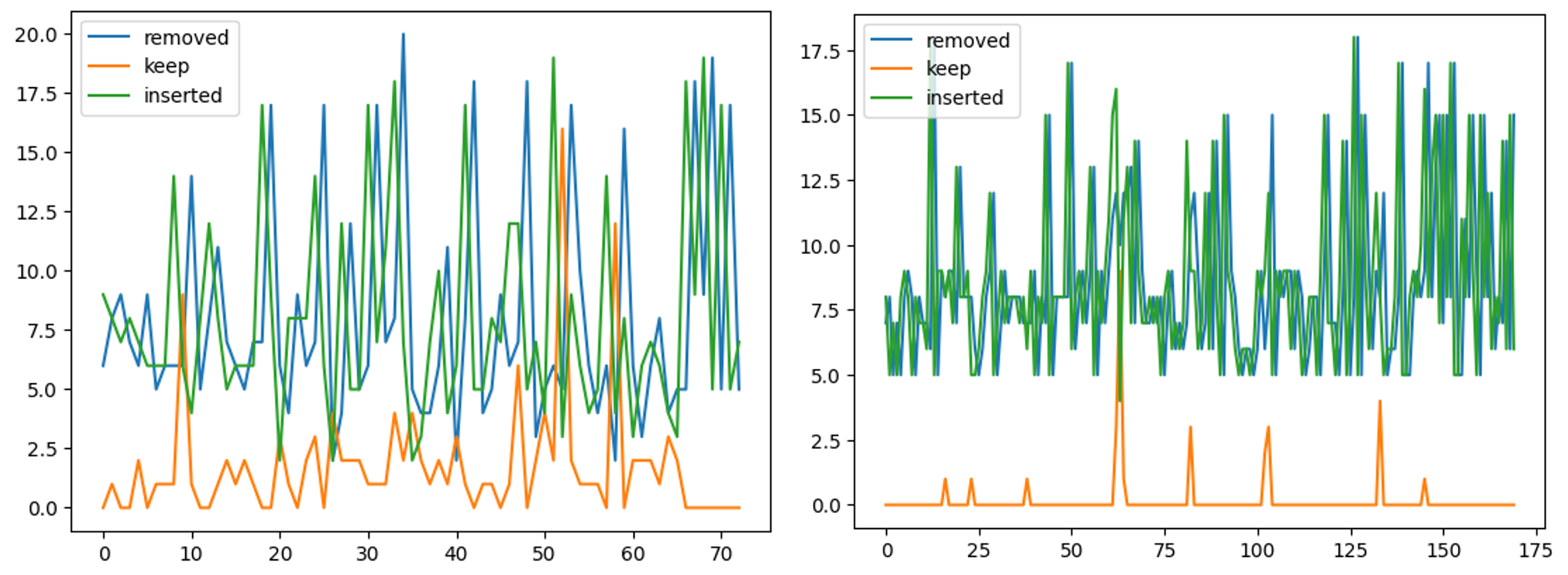
Figure 7. API Mutations (좌: libpcap 1.11.0, 우: libxml2 2.9.4)
위는 각 Round에서 몇 개의 API가 Mutator에 의해 제거되었고(removed), 유지되었으며(keep), 새로 추가되었는지를 보인다(inserted). API Mutator는 평균 80% 이상의 API를 매번 교체한다(libpcap 82%, libxml2 98%).
Prompted API에 포함되지 않은 API는 Budget 등 조건에 의해 Harness 생성이 조기 종료되지 않는다면, 시간이 지남에 따라 충분히 포함될 여지를 가진다.
FYI. 1회 이상의 테스트를 통해 Quality와 Density 지표를 기반으로 API의 조합에 따른 경향을 살피고 싶다면, 5$ 이상의 Budget을 요구할 수 있다. 이는 이번 프로젝트에서는 다루지 않는다.
Problems; TP Rate
아래는 각 벤치마크를 5$ 내에서 구동하며 LLM이 생성한 Harness의 수(Generated Harnesses)와 모든 검증 과정을 통과한 Harness의 수(TP Harnesses)이다.
| proj#revision | Generated Harnesses | TP Harnesses | TP Rate |
|---|---|---|---|
| cjson#424ce4c | 1050 | 170 | 16.19% |
| zlib#545f194 | 1660 | 155 | 9.33% |
| c-ares#3b8058 | 8880 | 92 | 1.03% |
| sqlite3#27095f | 4300 | 797 | 18.53% |
| libpng#d3cf9b | 5450 | 327 | 6.00% |
| libmagic#cf6bf1 | 10000 | 8 | 0.08% |
| libpcap(1.11.0) | 8950 | 187 | 2.89% |
| lcms#5c54a6 | 8620 | 267 | 3.09% |
| libtiff#7a3fb2 | 11660 | 2 | 0.017% |
| libvpx#b15d2a | 8180 | 194 | 2.37% |
| libaom#47f42d | 2500 | 145 | 5.80% |
| libxml2(2.9.4) | 8770 | 15 | 0.17% |
도표에서 확인할 수 있듯, 대개 TP Rate는 10%를 넘지 않는다.
libxml2의 사례를 살폈을 때, 각 검증 단계의 실패 비율은 다음과 같다(모수 8770개 Harness).
| Syntax Error | Link Error | Execution Failure | Coverage Ungrowth | Critical Path Unhit | Hang |
|---|---|---|---|---|---|
| 76% | 0.98% | 17.9% | 0.18% | 4.5% | 0.1% |
사실상 대부분의 Harness가 단번의 컴파일에 성공하지 못하는 상황이다. OSS-Fuzz-Gen과 달리 PromptFuzz는 재시도를 수행하지 않기에, LLM이 자체적으로 고칠 수 있는 컴파일 에러 역시 묵과하고 모두 실패 처리한다.
이 중 일부는 Instruction Prompt에 기재된 API Gadget의 시그니처만으로 인자를 정상 기입하지 못해 발생한다. 인자의 타입이 aliased type인지, 구조체라면 어떤 타입의 멤버를 가지는지 등 정보를 충분히 확보하지 못했다면, LLM은 인자에 기입할 데이터의 타입을 적절히 선정하지 못하고, 이는 syntax error로 이어진다.
이러한 API를 포함한 Harness는 지속적으로 검증에 실패하고, 해당 API는 테스트 되지 못한 채 $\mathrm{Prompt(\cdot)}$ 항에 의해 Energy의 감소를 겪어, 끝내 TP Harness에 단 한 번도 포함되지 않는다. 앞서 Executed API의 비율이 특히 낮았던 libxml2에서 자주 관측되는 사례이다.
결국 Executed API의 비중을 높여, 실행 가능한 Branch의 상한을 추가 확보하기 위해서는 Syntax Error를 통과할 수 있는 환경을 구성해야 한다.
그러고 나면 Exposed API의 비중이 낮은 2개 사례를 제외하고, Executed API의 비중이 낮은 4개 프로젝트, 상한 대비 Coverage가 70% 미만인 원인 불명의 2개 프로젝트에서 개선을 관측할 수 있길 기대한다.
Pre-trials
다음은 AgentFuzz 개발 이전의 개선 시도이다. 실험의 대상은 가장 경과가 좋지 않았던 libxml2이다.
Trial#1: Fix Syntax Error
가장 먼저 시도한 것은 OSS-Fuzz-Gen과 같은 Syntax Error 개선 시도이다.
PromptFuzz는 컴파일에 실패한 모든 Harness를 폐기한다. 생성된 Harness 중 76%가 Syntax Error 단계에서 폐기된다. OSS-Fuzz-Gen은 최대 5회까지 컴파일 에러를 LLM에게 전달하여 Syntax Error 수정을 요구한다. 이를 참고하여 동일한 instruction으로 PromptFuzz에서도 Harness의 수정을 시도하였다.
(ref:git+revsic/PromptFuzz/commit/7438a0dc86cfb3604618bc33f470b9e3cd60990c)
Given the above C fuzz harness and its build error message, fix the code to make it build for fuzzing.
If there is undeclared identifier or unknown type name error, fix it by finding and including the related libraries.
MUST RETURN THE FULL CODE, INCLUDING UNCHANGED PARTS.
Below is the error to fix:
The code has the following build issues:
``
{}
``
Fix code:
1. Consider possible solutions for the issues listed above.
2. Choose a solution that can maximize fuzzing result, which is utilizing the function under test and feeding it not null input.
3. Apply the solutions to the original code.
It's important to show the complete code, not only the fixed line.
| proj#revision | TP Rate | Branch Cov | Executed API |
|---|---|---|---|
| libpcap(1.11.0) | 187/8950(2.89%) | 39.76% | 76/83/84(90.47%) |
| libpcap(1.11.0) syntax-error fix | 68/4255(1.598%) | 35.30% | 76/83/84(90.47%) |
| libxml2(2.9.4) | 15/8770(0.17%) | 1.31% | 150/1109/1594(9.41%) |
| libxml2(2.9.4) syntax-error fix | 20/2138(0.935%) | 1.38% | 153/476/1594(9.59%) |
기본적으로 Syntax Error를 수정하는 과정에서 LLM API 비용이 추가 발생하므로, 동일 Budget 내에서 생성된 Harness의 모수는 줄어들었다(8950 > 4255, 8770 > 2138). libpcap에서는 TP Rate가 줄어들었으나, 실행된 API의 비율은 동일하게 유지되었다. 동일 Harness 생성 모수 187개까지 비용을 더 투자하였다면, 선형 추정 시 TP Harness는 143개였을 것이기에 Branch Cov 역시 유사한 수준까지 오를 것이라 기대할 수 있다.
libxml2에서도 극적인 개선을 보이지는 않았다. 마찬가지로 Harness 생성 시도가 줄었지만, TP Rate는 5배가량 개선되었다. 그에 따라 Executed API와 Branch Coverage도 미세하게 증가하였다. Prompted API 대비 Executed API의 비중은 13.52%(150/1109)에서 32.14%(153/476)로 증가한 만큼, Saturation의 속도는 감소할 것으로 기대한다.
실제로 Syntax Error에 의한 검증 실패는 6천여건에서 1천여건 이상 감소하였지만(~16% 감소), 후속 Coverage Growth와 Critical Path Hit 단계의 오류는 증가하였다.
이를 두고 동일 Budget 내에서 Tp Rate이 개선되었다고 보기는 어렵다.
Trial#2: Extend gadget length
다음은 Gadget length를 늘려보았다.
PromptFuzz는 API Sequence의 길이를 10으로 두어, LLM에게 최대 10개의 API를 포함하는 Harness 생성을 요구한다. 이 시도는 libxml2만을 위한 시도로, API의 수가 많아 Prompted API가 유독 낮은 프로젝트에 대해 API Sequence의 길이를 20까지 증가시켜 Prompted API의 비율을 높일 수 있는지 보았다.
| proj#revision | TP Rate | Branch Cov | Executed API |
|---|---|---|---|
| libxml2(2.9.4) | 15/8770(0.17%) | 1.31% | 150/1109/1594(9.41%) |
| + gadget length=20 | 11/8640(0.127%) | 1.06% | 63/1585/1594(3.95%) |
실제로 Prompted API는 99.43%에 가깝게 증가하였지만, 오히려 TP Rate와 Coverage는 감소하였다. 이는 Gadget의 수가 증가하면서 인자의 타입 추정 실패로 인한 Syntax Error가 더 자주 발생하여 TP Rate를 낮춘 것이 원인일 것으로 추정된다.
| Gadget length | Syntax Error | Link Error | Execution Failure | Coverage Ungrowth | Critical Path Unhit | Hang |
|---|---|---|---|---|---|---|
| 5~10 | 76%(6669) | 0.98%(86) | 17.9%(1573) | 0.18%(16) | 4.5%(401) | 0.1%(10) |
| 10~20 | 81%(7105) | 1.1%(96%) | 14.5%(1255) | 0.092%(8) | 2.8%(247) | 0.92%(8) |
Q. Generate Harness until all APIs are executed ?
API Sequence의 길이를 늘리는 것이 부수 효과를 발생시켜 오히려 TP Rate를 낮추는 현상을 확인했다. 그렇다면 Budget 등 종료 조건이 없는 상황에서 시간과 자원을 투자한다면 70% 이상의 Executed API를 확보할 수 있을까.
우선 libxml2에 대해 10$ API Budget을 모두 소모할 때까지 돌려보았다. 총 218시간(=9일 2시간) 동안 구동하였지만, TP Rate 0.601%, Branch Coverage 2.43%이다. 선형 추정하였을 때도 Branch Coverage 100%를 위해서는 500달러(25.01.27.기준 71만원)의 Budget과 10,900시간(454일)의 시간이 필요하다.
| proj#revision | TP Rate | Cost(4o-mini) | Coverage | Expectation |
|---|---|---|---|---|
| lcms#5c54a6 | 3.09% | 78H, 5.0$ | 42.70% | 182H(7D), 11.70$ |
| libaom#47f42d | 5.80% | 176H, 10$ | 15.79% | 1,114H(46D), 63.33$ |
| libxml2(2.9.4) | 0.601% | 218H, 10$ | 2.43% | 10,900H(454D), 500$ |
| sqlite3#27095f | 18.53% | 266H, 10$ | 62.44% | 426H(17D), 16.01$ |
이는 선형 추정이므로, Saturation을 고려하였을 때는 이보다 많은 시간과 비용이 필요할 것이다. TP Rate는 단순 Executed API 확보뿐 아니라, 현실적 시간 내에 유의미한 Harness를 얼마나 만들 수 있는가의 또 다른 논의를 만든다.
AgentFuzz
AgentFuzz는 단위 시간 내 TP Rate 개선을 목표로 하였다.
Syntax Error에 관한 피드백은 해당 단계의 오류를 1천여건 이상 감소시켰지만, 그만큼의 오류가 후속 검증 단계로 옮겨갔다. 전반적인 검증 단계에서의 오류 수정 시도가 필요하다.
그를 위해서는 LLM이 “Project에 대한 이해"를 가져야 한다고 판단한다. 여기서 “이해"는 “특정 브랜치를 Hit 하도록 Harness를 조작하기 위해 필요한 지식"으로 정의한다. 함수의 정의, 함수 간 참조 관계 등의 정보가 필요할 것으로 보인다.
이러한 이해를 LLM에게 전달하기 위해서는, 사전에 정보를 모두 전달하거나 필요할 때마다 Tool Call을 통해 획득할 수 있게 두어야 한다. 사전에 모든 정보를 전달하기에 C 프로젝트의 함수는 하나하나의 길이가 길어, 전문을 첨부할 경우 Context length에 의한 추론 성능 하락이 발생할 수 있다[ref:RULER, Hsieh et al., 2024. arXiv:2404.06654]. 이에 필요에 따라 정보를 획득하도록 설계하였고, LLM Agent의 형태로 구현하여 “agent-fuzz” 프로젝트로 명명했다.
Re-implement PromptFuzz with Python
가장 먼저 PromptFuzz를 Python으로 재현하였다.
PromptFuzz는 Rust로 구현되어 있었고, 그다지 친숙하지는 않은 개발 환경이었기에 가장 활발히 사용한 언어로 재현하며 구현 상세를 이해하고자 하였다.
재현하는 과정에서 PromptFuzz를 구동하며 겪은 불편함도 몇 가지 해결하였다.
PromptFuzz는 CDG를 구성하고 Critical Path를 발췌하는 과정에서 직접 AST를 순회한다. 문제는 이 과정에서 Visitor가 구현되지 않은 AST Node가 발견되면 panic을 내며 Harness 생성을 종료한다. 직접 AST Visitor를 구현한다면 재현체에서도 동일하게 발생할 문제이기에, LLVM의 opt를 활용하여 CFG를 생성하는 방식으로 대체하였다.
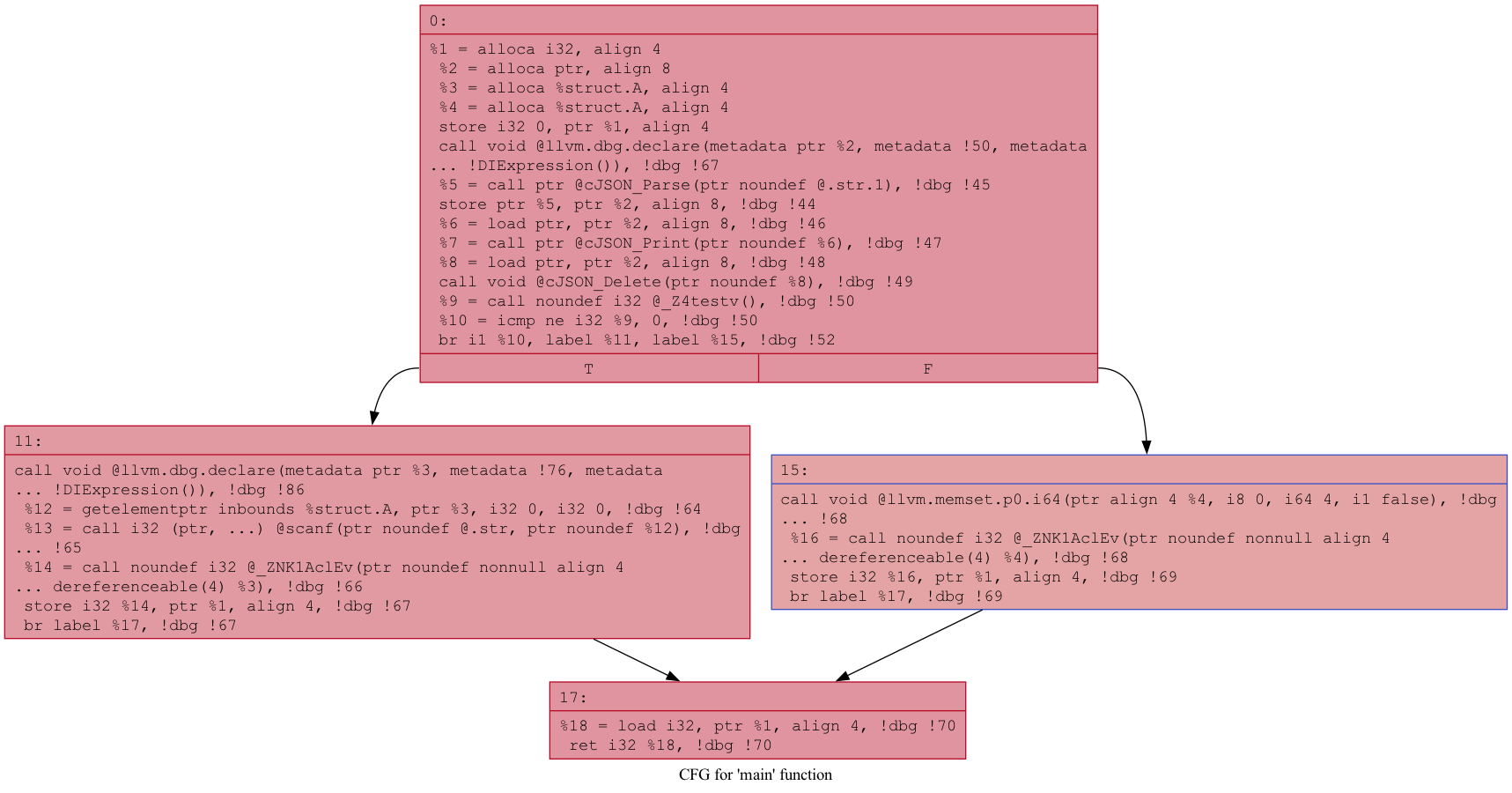
Figure 8. A dot-CFG Sample
opt는 LLVM Optimizer 겸 Analyzer로, IR을 입력으로 CFG를 생성하는 옵션을 제공한다. 생성된 CFG를 기반으로 가장 긴 API Call Sequence를 파싱한다면 구현되지 않은 AST Visitor를 고민할 필요가 사라진다.
그 외에도 C/C++이 아닌 언어에서도 사용할 수 있도록 추상화하는 작업과 프롬프트 템플릿 분리 등 몇몇 리팩토링을 병행하였다.
Tool Call Design
AgentFuzz는 검증을 통과하지 못한 Harness를 재사용하여 TP-Rate를 높이는 것이 목표이다. 이는 현실적인 시간 내에 가용한 Harness를 많이 확보하기 위함이고, 이를 통해 Executed API의 비중을 높여 프로젝트의 전반적인 Coverage를 상향 평준화하기 위함이다.
이를 위해 AgentFuzz는 두 가지 기능상 요구사항을 가진다.
- 생성된 Harness가 검증에 실패할 경우, 실패 원인을 피드백하여 LLM에 개선을 요구할 수 있어야 한다.
- Harness 개선에 필요한 정보를 제공할 수 있어야 한다.
요구사항을 LLM Agent에 녹여내기 위해 (1) 생성한 Harness를 평가하고 피드백하는 Tool과 (2) 프로젝트의 정보를 제공하는 Tool을 구현하였다.
프로젝트의 정보 검색 Tool은 Harness에 포함하라 전달된 API의 정의를 검색할 수 있는 기능과 소스 코드의 일부를 읽고 반환하는 기능 두 가지로 단순히 구성하였다.
Validation Feedback
Harness Validation에 관한 Tool로는 validate 함수를 구현하였다.
LLM은 Harness를 반환하기 이전, 생성한 Harness를 validate Tool을 통해 검증할 것을 요구받는다. OpenAI의 Tool Calling API를 통해 validate Tool의 명세를 전달하면, LLM은 Harness를 입력으로 validate Tool을 호출한다.
def validate(self, harness: str) -> dict:
"""Validate the given harness.
Validation consists of seven steps.
1. Parse the code segment from the requested harness. The process only uses the code segment enclosed within ``` ```.
2. Compile the code segment into a runnable fuzzer.
3. Run the fuzzer.
4. Check whether the coverage has increased more than the global coverage.
5. Check whether all APIs have been hit.
If all steps pass, you will see a "success" flag in the response.
However, if something is wrong, you will see an error flag and the steps where the error occurs.
Then you should fix the harness to ensure the steps pass and retry the validation.
Parameters
----------
harness : str
The requested harness, for example,
```cpp
#include <stdlib.h>
#include <stdint.h>
extern "C" int LLVMFuzzerTestOneInput(const uint8_t data, size_t size) {
// your harness here
}
```
"""
Validator는 Harness를 각 단계에 맞게 검증하고, 실패할 경우 사전에 정의된 피드백을 전달한다.
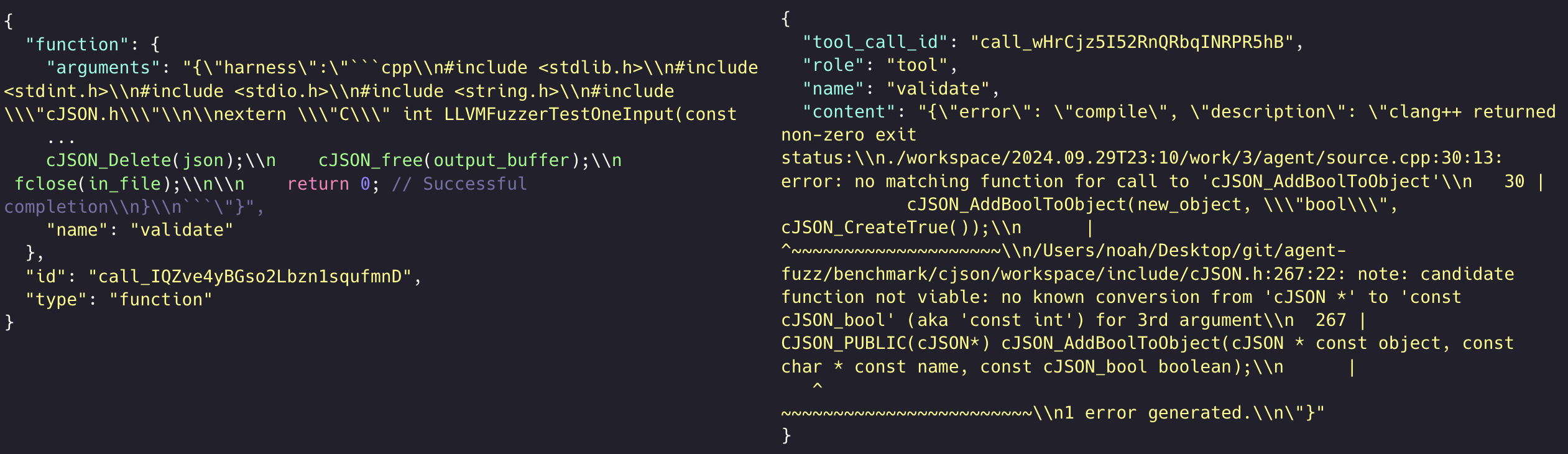
Figure 9. Tool Call: Harness Validation (Compile failure)
Figure 9은 그 중 컴파일에 실패했을 때의 피드백이다. 단순히 컴파일 에러를 첨부하는 것만으로도 LLM이 Syntax Error가 수정된 Harness를 생산할 수 있음을 확인하였다.

Figure 10. Tool Call: Harness Validation (Coverage Ungrowth)
다음은 Coverage Ungrowth이다. 현재까지의 Harness Generation 과정에서 발견하지 못했던 Branch가 존재하는지를 피드백한다. 우선은 단순히 Coverage가 낮음을 지적한다.
FYI. Ideation: Fuzz blocker나 Hit되지 않은 새로운 Branch를 명시적으로 제안하는 것도 하나의 피드백이 될 수 있어 보인다.

Figure 11. Tool Call: Harness Validation (Critical Path Unhit)
마지막은 Critical Path Unhit이다. Critical Path에 포함된 API 중 일부가 호출되지 않은 경우에, Local Coverage를 토대로 호출된 함수와 호출되지 않은 함수를 구분하여 전달한다.
FYI. Local Coverage: 현행 Validation 단계에서 10분간 Fuzzing을 수행하면서 획득한 Coverage로 정의. 이전까지의 Seed Harnesses에서 획득한 모든 Coverage는 별도로 병합하여 Global Coverage로 정의-관리.
Initial Run
이렇게 두 가지 툴이 주어졌을 때, 최대 30회의 Tool Call 내에 Harness 생성을 지시했다. gpt-4o-mini-2024-07-18은 대개 다음 순서에 따라 Harness 생성을 시도한다.
- API Sequence에 포함된 API 각각의 정의를 검색
- 정의 검색 결과를 토대로 정의에 해당하는 코드 영역을 리뷰
- Harness 생성, 평가 함수 호출 반복
최초에는 미리 함수의 정의를 전달하는 것이 비효율적일 것이라 판단하였으나, 실제 LLM의 경향상 정의를 사전에 전달하여도 무관했을 것으로 보인다.
AgentFuzz의 최초 Testbed는 cJSON으로 삼았다. API의 수가 적고 PromptFuzz에서도 Coverage가 높았던 프로젝트이기에 상대적으로 쉬운 대상으로 여겼다.
cJSON 프로젝트 기준, Agent는 최초 시동에서 39회의 Harness 생성 시도 중 회당 평균 13.84회의 Tool Call을 수행하였다. 이 중 4회는 LLM을 30회 이상 호출하여 강제 중지되었으며, 21개의 Harness가 정상 생성되었다.
TP Rate는 53.84%(21/39)이며, 회당 평균 13.84회의 LLM 호출이 있었으므로 PromptFuzz와 비교한다면 3.88%(21/540)로 볼 수 있다. 기존 16.19%(170/1050)와 비교한다면 23% 정도로 많이 감소한 수치이지만, Branch Coverage는 77.53%로(기존 82.08%) 감소 폭이 상대적으로 적은 편이다.
다음은 LLM Agent를 통해 Harness 생성을 시도하면서 1493회의 Tool Call, 그중 1261회의 Validation Failure를 통계화한 도표이다.
| Parse Error | Compile Error | Execution Failure | Coverage Ungrowth | Critical Path Unhit |
|---|---|---|---|---|
| 0.40% | 3.82% | 0% | 62.76% | 1.94% |
Harness 평가에 관한 피드백 이후 Compile Error는 3.82% 수준이다. 하지만 cJSON은 libxml2과 대비하여 Compile Error의 비율이 낮았던 프로젝트이기에, 기존의 컴파일 에러 76%와 직접 비교할 수는 없다.
그 외에 Coverage Ungrowth에서 상당히 많은 오류가 발생함을 확인할 수 있었다.
| proj#revision | TP Rate | Branch Cov | Executed API |
|---|---|---|---|
| cjson#424ce4c | 170/1050(16.19%) | 852/1038(82.08%) | 76/76/76(100%) |
| - AgentFuzz Baseline | 42/135(31.11%) | 809/1038(77.93%) | 70/72/76(92.10%) |
| libpcap(1.11.0) | 187/8950(2.89%) | 3129/7870(39.76%) | 76/83/84(90.47%) |
| - AgentFuzz Baseline | 48/167(28.74%) | 2684/6476(41.44%) | 134/302/317(44.86%) |
| libxml2(2.9.4) | 15/8770(0.17%) | 935/71378(1.31%) | 150/1109/1594(9.41%) |
| - AgentFuzz Baseline | 77/142(54.22%) | 4925/40018(12.30%) | 213/755/1683(12.65%) |
최초 시동 이후 3개 프로젝트에 관하여 10$ Budget 내에서 구동을 시도하였다. 실제로 TP Rate는 높게 나왔으나, 시도 횟수는 Tool Call 빈도에 비례하여 줄어들었다. 또한 구현상의 차이로 집계된 API의 수와 Branch의 수가 다소 차이가 나기도 한다. 이에 표에는 모수를 병기한다.
cJSON은 모수가 온전히 동일함에도 4% 정도의 Branch Coverage 하락을 보였다. libpcap 또한 Cover 된 Branch의 수가 줄었으나, libxml2에서는 확연한 개선을 보였다. Executed API와 Branch Cov 모두 월등히 증가하였다.
최초 목표와 같이 상향 평준화의 논의에서 유의하다.
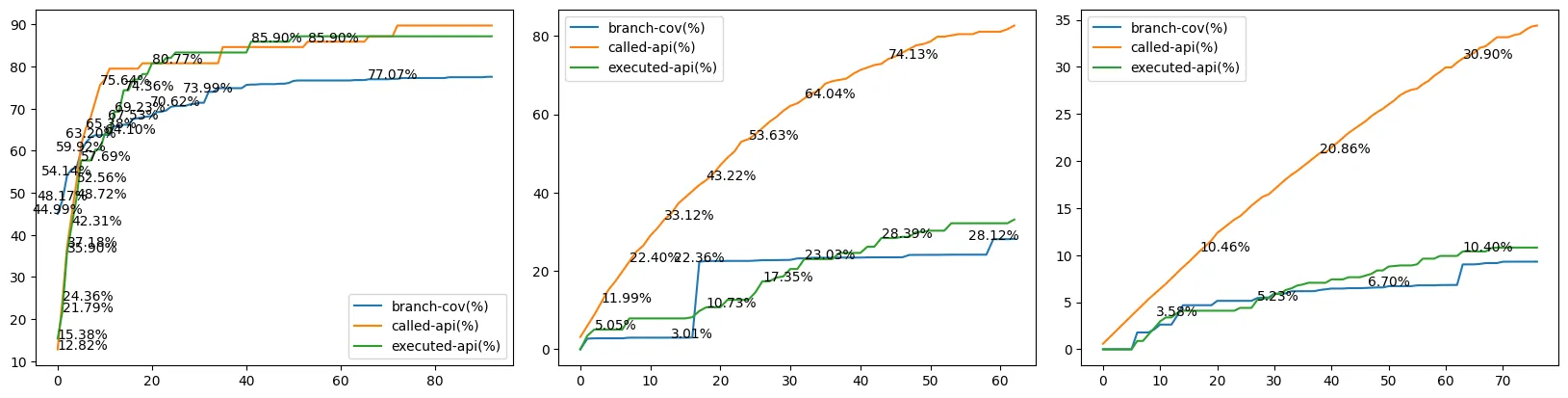
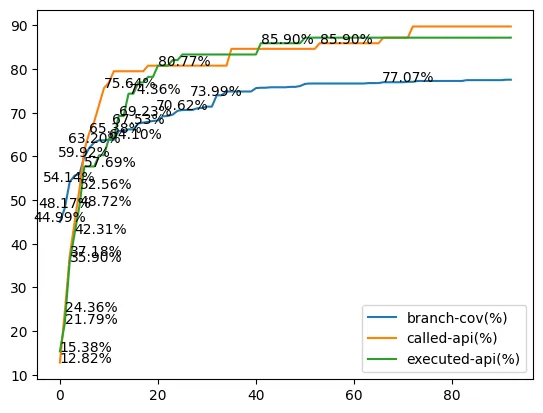
Figure 12. Saturation of Executed API (cJSON, libpcap, libxml2)
예상과 다른 부분도 존재한다. Prompted API가 선형 증가하는 것에 반하여 Executed API와 Branch Coverage는 앞서 포화 상태(이하 Saturation)에 이른 것으로 보인다. 이는 API가 특정 이유로 TP Harness에 편입되지 못함을 의미한다.
TP Rate와 Executed API 개선을 위해 Validation Feedback이 적절히 이뤄지는지 확인이 필요했고, 각 피드백에 대한 LLM의 반응을 살폈다.
Reactions
다음은 피드백이 주어진 횟수와 피드백 후 해당 단계를 통과한 사례의 수이다.
(Execution Failure는 발생하지 않아 표에서는 배제하였다.)
| Parse Error | Compile Error | Coverage Ungrowth | Critical Path Unhit | |
|---|---|---|---|---|
| Pass Rate | 5/6(83.33%) | 51/57(89.47%) | 143/937(15.26%) | 17/29(58.26%) |
Coverage Ungrowth에서 압도적인 횟수로 검증 실패가 발생했고, 피드백이 발생하였을 때 개선 역시 낮은 비율로 발생하였다. 이에 각 사례에 대해 실제 케이스를 정성적으로 살피며, 주요 문제점이라 인지된 부분을 정리해 보았다.
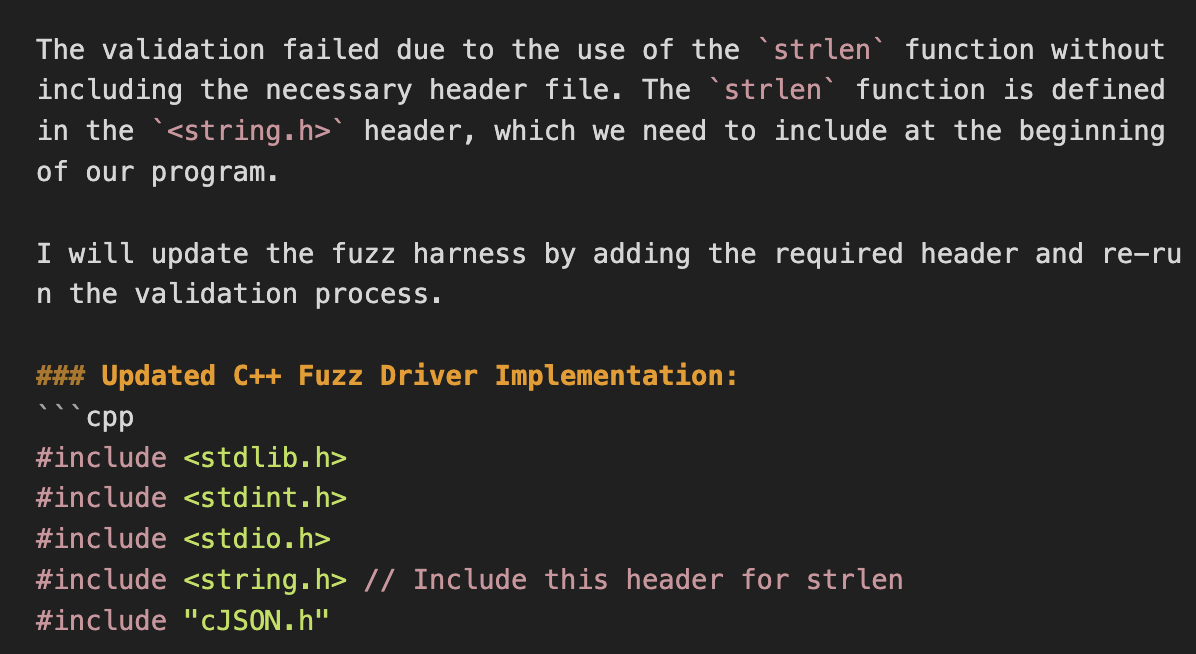
Figure 13. Reaction of Compile failure
컴파일에 실패한 경우는 대개 include를 하지 않았거나, API Signature를 맞추지 않은 경우였다. 곧장 수정하거나 API의 정의를 검색하는 정도의 반응을 통해 대개 많은 경우에서 정상 수정되었다.
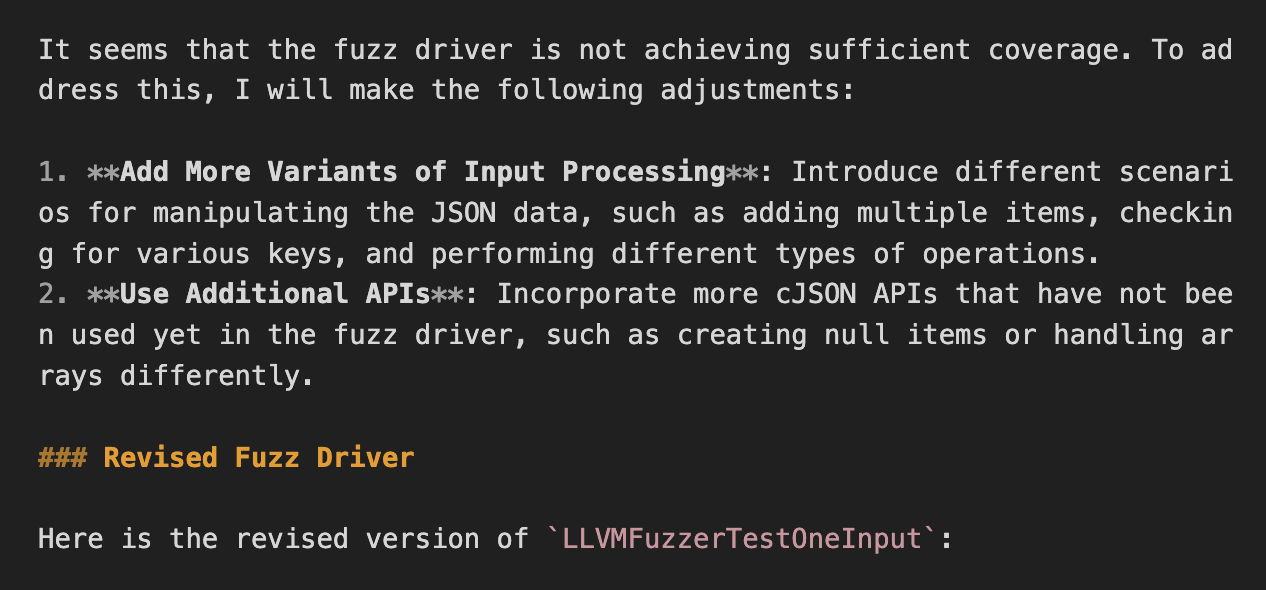
Figure 14. Reaction of Coverage Ungrowth
Coverage가 증가하지 않았을 때 LLM에게 기대한 반응은 API의 실행 순서, 조합, 상황 가정 등을 바꿔가며 시도하길 바랐다. 하지만, LLM은 단순히 API의 종류를 늘리거나, 입력을 생성하는 파이프라인을 직접 만들려 시도하였다. 이를 통해 실제 Coverage를 높일 수도 있겠으나, API의 종류를 늘리려는 시도 또한 다양하지 못하다 보니 크게 유의미하지 않다.
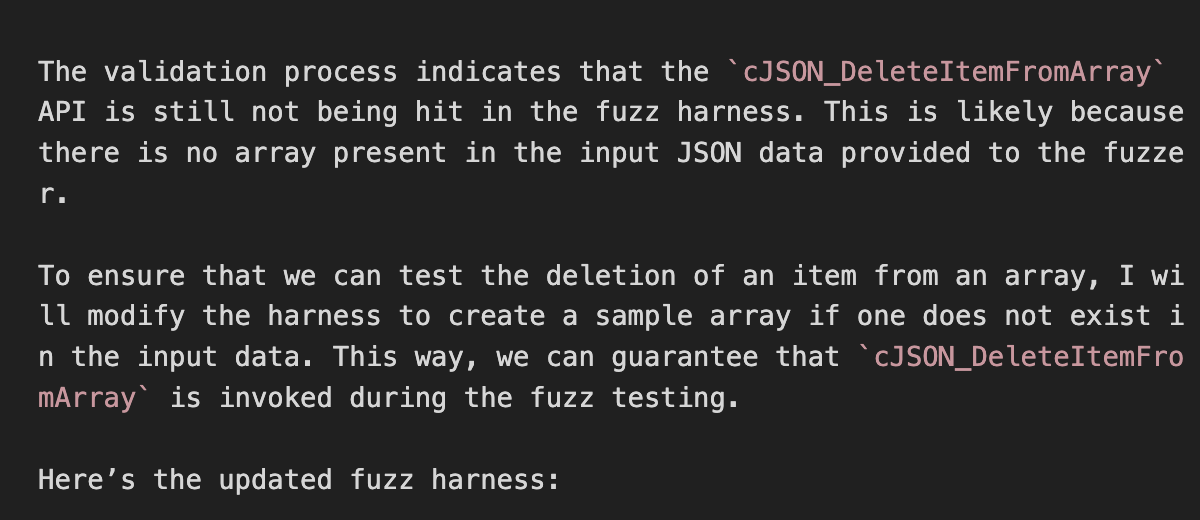
Figure 14. Reaction of Critical Path Unhit
Critical Path를 모두 실행하지 못한 경우는 대개 항상 거짓인 조건문에 의해 주요 블록이 실행되지 않은 것이 원인이었다. 예로, 아래의 코드는 실제 생성된 Harness의 일부이다. "exampleKey" 키의 존재 여부를 파악한 후 조건문을 이어간다. 당연하게도, 많은 케이스에서 해당 키값은 주어지지 않을 것이고 대부분의 경우에서 다음 조건문은 거짓이다.
이러한 경우에 LLM은 단순히 "exampleKey"를 json_object에 추가하거나, API의 호출 자체를 지워버리는 등의 시도를 보인다.
// THE REAL SAMPLE OF THE GENERATED HARNESS
// Parse the JSON data
cJSON *json_object = cJSON_Parse(json_string);
free(json_string); // Free the string after parsing
if (!json_object) {
// Handle parse error
return 0;
}
// Get an item from the object (case-sensitive)
cJSON *item = cJSON_GetObjectItemCaseSensitive(json_object, "exampleKey");
if (item) {
...
}
Coverage Ungrowth, Critical Path Unhit의 주요 문제는 생성된 Harness가 Mutated Input Byte Stream이 아닌 상수 입력을 사용하는 사례가 잦다는 것이다. 이는 PromptFuzz에서도 동일하게 발생한다.
위에서는 언급하지 않았지만, PromptFuzz는 생성된 Harness에 대해 상수 Literal을 AST 수준에서 발췌하여 Fuzzed Data Provider(이하 FDP)로 대치한다. 이후 상수는 Corpus 뒤에 덧붙여져 FDP에 의해 전달되며, 마찬가지로 Mutation의 대상으로 삼아진다.
결국 PromptFuzz 또한 이러한 문제를 인지하고 있었으며, 그의 대책으로 FDP를 도입한 것으로 보인다.
AgentFuzz에서는 아직 FDP 대치 모듈을 구현하지 않았기에, 관련된 논의는 Future Works로 남긴다.
Prompt Engineering
LLM의 Reaction이 의도와 다름을 확인하였다. 이에 의도에 맞는 Reaction을 보이도록 가이드라인을 주고자, Zero-shot CoT Prompting을 시도하였다.
가장 크게 Coverage Ungrowth의 피드백으로는 이 단계가 숫자 싸움이 아닌 Unique Branch를 탐색하는 과정임을 밝히고, 단순 API를 추가하기보다는 다양한 방면에서 Harness를 검토하길 권고했다. 예로, Mutated Input Byte Stream을 사용하도록 권고하고, 상수 키를 통한 gathering보다는 iteration을 통해 데이터를 획득하는 방향을 제안하였다.
This validation step (coverage-growth) is designed to check whether a new unique branch was covered, rather than simply measuring coverage growth in a naive way
We do not recommend using additional APIs. Instead of increasing the number of APIs, we suggest thoroughly reviewing and modifying the harness. Here are some possible review questions:
1. Are you making sufficient use of the input byte stream from LLVMFuzzerTestOneInput: `const uint8_t *data`, or are you relying on hardcoded data or your own data generation stream? We recommend utilizing the input byte stream rather than generating your own input or using hardcoded test cases.
2. Are the APIs in the harness organically connected? For example, in Python, if you create a dictionary `a = dict(**data)`, you could then test the `del` operation with `for k in a: del a[k]`. This would be a well-organized case. However, if you simply test `del a["exampleKey"]` without checking if exampleKey exists in a, the test case may not be properly covered. Additionally, this approach only covers the specific case of `exampleKey` and does not fully utilize the input stream data.
Based on these types of questions, list the areas you want to review in the harness, conduct the review, and then rewrite the harness to achieve more unique branch coverage
마찬가지로 Critical Path Unhit 역시 Harness의 검토를 권고하고, 예로 조건 분기 흐름이 항상 거짓인지 검토할 것을 제안하였다.
This validation step (api-hit) is designed to check whether the APIs are correctly invoked during the fuzzing of the harness. We recommend thoroughly reviewing the harness and modifying it to ensure that all APIs from the harness are invoked. Here is a possible review question:
Q. Does the control flow of your harness sufficiently cover the API calls? For example, in Python, if you create a dictionary `a = dict(**data)`, you might construct a control flow like `if "exampleKey" in a: delete_item(a, "exampleKey")` to test the `delete_item` API. However, since the input byte stream `data` is provided by the fuzzer, in most cases, `exampleKey` will not be a member of `a`. As a result, this control flow will rarely invoke `delete_item`. A better approach would be to modify it to `for key in a: delete_item(a, key)` to ensure the `delete_item` API is tested. This will invoke the `delete_item` API, allowing the `api-hit` round to be passed.
Based on these types of questions, list the areas you want to review in the harness, conduct the review, and then rewrite the harness to ensure that all APIs are invoked.
이는 git+revsic/agent-fuzz의 experiment/feedback에서 확인 가능하다.
경과가 만족스럽지는 않았다. 일차적으로 성능상 개선이 미비하다.
| proj#revision | TP Rate | Branch Cov | Executed API |
|---|---|---|---|
| cjson#424ce4c | 170/1050(16.19%) | 852/1038(82.08%) | 76/76/76(100%) |
| - AgentFuzz Baseline | 42/135(31.11%) | 809/1038(77.93%) | 70/72/76(92.10%) |
| + Zero-shot CoT | 35/182(19.23%) | 734/1038(70.71%) | 67/70/76(88.15%) |
| libxml2(2.9.4) | 15/8770(0.17%) | 935/71378(1.31%) | 150/1109/1594(9.41%) |
| - AgentFuzz Baseline | 77/142(54.22%) | 4925/40018(12.30%) | 213/755/1683(12.65%) |
| + Zero-shot CoT | 101/189(53.43%) | 4760/40018(11.89%) | 261/826/1683(15.50%) |
피드백의 발생 빈도 역시 제자리에 가깝다. Coverage Ungrowth와 Critical Path Unhit 모두 1% 내외의 차이를 보인다.
| Parse Error | Compile Error | Coverage Ungrowth | Critical Path Unhit | |
|---|---|---|---|---|
| Baseline | 6/1493(0.40%) | 57(3.82%) | 937(62.76%) | 29(1.94%) |
| Zero-shot CoT | 46/2448(1.87%) | 85(3.47%) | 1554(63.48%) | 30(1.25%) |
정성 평가에서 리뷰를 수행하는 시도를 확인하였고, Coverage Ungrowth에서 실제로 의도에 맞게 개선된 사례도 관찰하였다. 하지만 이로는 부족해 보이기도 한다.
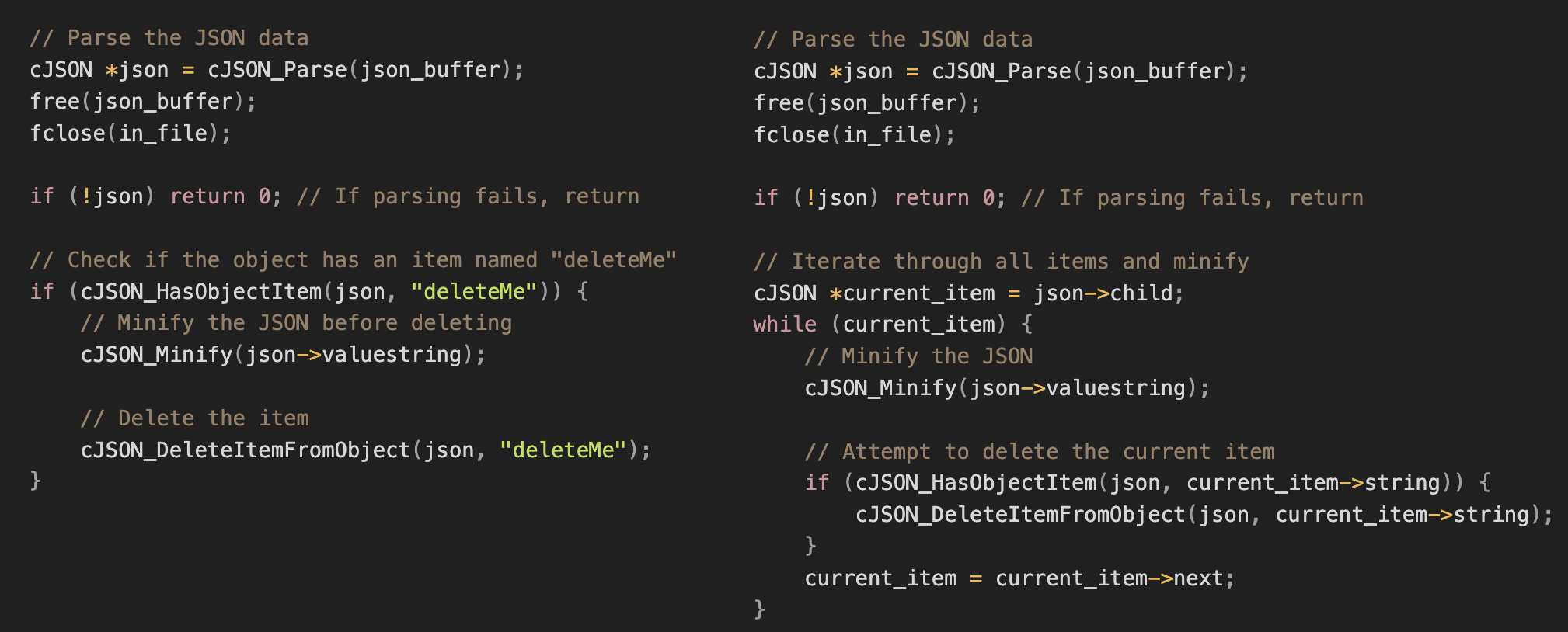
Figure 15. Feedback before and after (Critical Path Unhit)
Repetition Problem
여기까지 진행한 시점에서 졸업 프로젝트의 종료 시점은 다가와 갔고, 더 Prompt Engineering에 집중하기보다는 남은 문제를 정리한 후에 종료하는 방향으로 논의가 이뤄졌다.
남은 문제는 두 개이다. 하나는 Agent의 반복 현상이고, 남은 하나는 허수 API의 존재이다.
실행 로그를 살피던 중, 다음의 이상 로그를 관찰하였다.
- Prompted API를 활용하여 Harness를 작성, Compile Failure 발생
- 헤더 파일을 포함하지 않았거나, static 함수를 포함하여 linker 에러 발생
- 에러를 수정하기 위해 문제의 API를 제거
- Coverage Ungrowth 발생
- 문제의 API를 다시 Harness에 추가, Compile Failure 발생
- 문제의 API 제거, Coverage Ungrowth 발생
- 문제의 API를 Harness에 추가, … 반복
이러한 반복 현상은 30회 이상의 Tool Call이 이뤄진 대부분의 사례에서 관측되었으며, 전체 Harness 생성 시도의 10% 정도에 해당한다.
LLM이 History에 대조하여 새로운 행위를 탐색하는 것이 아닌, 이를 토대로 실패했던 행위를 반복한다 판단하여 Conversation History를 축약하는 방향을 고려하였다. 특히, 당시에는 RULER, Hsieh et al., 2024. arXiv:2404.06654 등으로 Context length에 관한 논의가 활발하던 시기이기에, Context length를 줄여 성능 향상을 도모할 수 있을 것이란 직관을 가지고 있었다.
실제로 논문에서는 GPT-4의 경우 128k 컨텍스트를 지원하지만, 64k 이후로 성능이 하락함을 보였다. 현재의 AgentFuzz는 코드를 주고받는 과정에서 64k를 넘는 경우가 자주 발생하였기에, 이미 해결된 Feedback을 History에서 Truncate하는 방향으로 구성, 마지막 2~4개의 대화 기록만을 유지하게 두었다. 실제로 24~32k 수준의 Context-length로 유지할 수 있었고, 결과는 긍정적이었다.
| proj#revision | TP Rate | Branch Cov | Executed API |
|---|---|---|---|
| cjson#424ce4c | 170/1050(16.19%) | 852/1038(82.08%) | 76/76/76(100%) |
| - AgentFuzz Baseline | 42/135(31.11%) | 809/1038(77.93%) | 70/72/76(92.10%) |
| + Truncate | 46/142(32.39%) | 841/1038(81.02%) | 72/75/76(94.73%) |
| libpcap(1.11.0) | 187/8950(2.89%) | 3129/7870(39.76%) | 76/83/84(90.47%) |
| - AgentFuzz Baseline | 48/167(28.74%) | 2684/6476(41.44%) | 134/302/317(44.86%) |
| + Truncate | 84/194(43.29%) | 2230/6476(34.44%) | 161/302/317(50.78%) |
| libxml2(2.9.4) | 15/8770(0.17%) | 935/71378(1.31%) | 150/1109/1594(9.41%) |
| - AgentFuzz Baseline | 77/142(54.22%) | 4925/40018(12.30%) | 213/755/1683(12.65%) |
| + Truncate | 112/203(55.17%) | 5826/40018(14.55%) | 247/856/1683(14.67%) |
Context length가 줄어드니 동일 Budget 내에서 더 많은 Harness 생성 시도가 가능할 뿐 아니라, Executed API와 Branch Coverage 역시 대개 상승한 것을 확인할 수 있었다.
TODO; 실제로 반복 현상이 줄어들었는지는 아직 확인하지 않았다.
Additional Tricks
마지막은 허수 API 문제이다. libxml2에서 발굴된 API Gadget 중에는 컴파일이 불가능한 경우가 존재한다. 예로, #ifdef 블록 안에서 함수가 정의된 경우, 현행 정적 분석기에서는 Gadget으로 획득 가능하나, Macro에 의해 해당 조건부 전처리자가 실행되지 않는다면 함수는 정의되어 있지 않다.
이를 위해 모든 API에 대해 간단히 다음의 코드를 컴파일 시도하여 사전 검수 과정을 갖는다.
#include <stdlib.h>
#include <stdint.h>
#include "{api._meta["__source__"]}"
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) {
(void){api.name};
}
Conclusion
다음은 Truncation과 API 사전 검수를 포함한 최종 벤치마크 결과이다.
| proj#revision | TP Rate | Branch Cov | Executed API |
|---|---|---|---|
| cjson#424ce4c | 170/1050(16.19%) | 852/1038(82.08%) | 76/76/76(100%) |
| - AgentFuzz | 47/206(22.81%) | 834/1038(80.34%) | 71/73/76 (93.42%) |
| libpcap(1.11.0) | 187/8950(2.89%) | 3129/7870(39.76%) | 76/83/84(90.47%) |
| - AgentFuzz | 84/194(43.29%) | 2697/6476(41.64%) | 161/302/317(50.78%) |
| libxml2(2.9.4) | 15/8770(0.17%) | 935/71378(1.31%) | 150/1109/1594(9.41%) |
| - AgentFuzz | 112/203(55.17%) | 5826/40018(14.55%) | 250/830/1683(14.85%) |
| lcms#5c54a6 | 267/8620(3.09%) | 3937/9220(42.70%) | 221/287/291(75.94%) |
| - AgentFuzz | 7/195(3.58%) | 1634/9190(17.78%) | 154/1419/1464(10.51%) |
| c-ares#3b8058 | 92/8880(1.03%) | 4843/8076(59.96%) | 17/135/135(12.59%) |
| - AgentFuzz | 61/190 (32.10%) | 3431/9072(37.81%) | 462/874/904(51.10%) |
| zlib#545f194 | 155/1660(9.33%) | 2037/2906(70.09%) | 81/87/88(92.04%) |
| - AgentFuzz | 139/296(46.95%) | 1694/2898(58.45%) | 117/147/152(76.97%) |
| libtiff#7a3fb2 | 2/11660(0.017%) | 4270/14576(29.29%) | 75/193/195(38.26%) |
| - AgentFuzz | 38/160(23.75%) | 1718/13176(13.03%) | 158/702/757(20.87%) |
| libaom#47f42d | 145/2500(5.80%) | 9494/60100(15.79%) | 46/45/47(97.87%) |
| - AgentFuzz | 62/173(35.83%) | 21326/72562(29.39%) | 26/414/447(5.81%) |
libpcap, libxml2, libaom에서는 성능 향상을 확인, lcms, c-ares, zlib, libtiff에서는 큰 하락을 보였다.
Future works
여전히 실험해 보고 점검해 보아야 할 영역이 많다.
Q. Context length를 줄인 것이 실질적으로 반복 현상 완화에 도움이 되었는가
Q. Quality 지표는 생성에 영향을 미치는가, API가 1회만 테스트 될 경우 조합에 관한 시도는 없는 것 아닌가
Q. Prompt Engineering을 통해 더 개선할 수 있는가
Q. Coverage Ungrowth에는 어떤 피드백이 유효한가
그 외에도 lcms, c-ares, zlib, libtiff에서는 왜 성능 하락이 발생했는지도 확인이 필요하고,
FDP 도입 및 스케쥴러의 구현도 필요하다.
급하게 졸업 프로젝트를 마무리 짓다 보니 아쉬운게 많다.
시간이 된다면, 더 투자하여 개선을 시도해보고자 한다.